Open access Y-chromosomal connection between Hungarians and geographically distant populations of the Ural Mountain region and West Siberia, by Post et al. Scientific Reports (2019) 9:7786.
Hungarian Conquerors
More interesting than the study of modern populations of the paper is the following excerpt from the introduction, referring to a paper that is likely in preparation, Európai És Ázsiai Apai Genetikai Vonalak A Honfoglaló Magyar Törzsekben, by Fóthi, E., Fehér, T., Fóthi, Á. & Keyser, C., Avicenna Institute of Middle Eastern Studies (2019):
Certain chr-Y lineages from haplogroup (hg) N have been proposed to be associated with the spread of Uralic languages. So far, hg N3 has not been reported for Indo-European speaking populations in Central Europe, but it is present among Hungarians, although the proportion of hg N in the paternal gene pool of present-day Hungarians is only marginal (up to 4%) compared to other Uralic speaking populations. It has been shown earlier that one of the sub-clades of hg N – N3a4-Z1936 – could be a potential link between two Ugric speaking populations: the Hungarians and the Mansi. It is also notable that some ancient Hungarian samples from the 9th and 10th century Carpathian Basin belonged to this hg N sub-clade: Three Z1936 samples were found in the Upper-Tisza area (Karos II, Bodrogszerdahely/Streda nad Bodrogom) and two in the Middle-Tisza basin cemeteries (Nagykörű and Tiszakécske). The haplotype of the Nagykörű sample is identical with one contemporary Hungarian sample from Transylvania that tested positive for B545 marker downstream of N3a4-Z193632. Similar findings come from the maternal gene pool of historical Hungarians: the analyses of early medieval aDNA samples from Karos-Eperjesszög cemeteries revealed the presence of mtDNA hgs of East Asian provenance.
A commenter recently wrote that in a study by Fehér (probably this one) two Hungarian conquerors, from Ormenykut and Tuzser, will be of hg. N1c-2110. Assuming no other lineages will appear, this would leave the proportion of N1c-L392 vs. R1a-Z280/Z93 closer to the reported proportion of hg. N vs. R1a (5 vs. 2) among Sargat samples, and is thus compatible with a direct migration of Hungarians from around the Urals.
However, the sampling of Iron Age populations around the Urals is scarce, and we don’t know what other lineages these studied Magyars will have, but – based on the known variability of the published ones, and on the ca. 50-60 early Magyar males available to date in previous studies to obtain Y-chromosome haplogroups – I would say these reported N1c lineages are just a tiny proportion of what’s to come…
“Altaic-Uralic” N1c
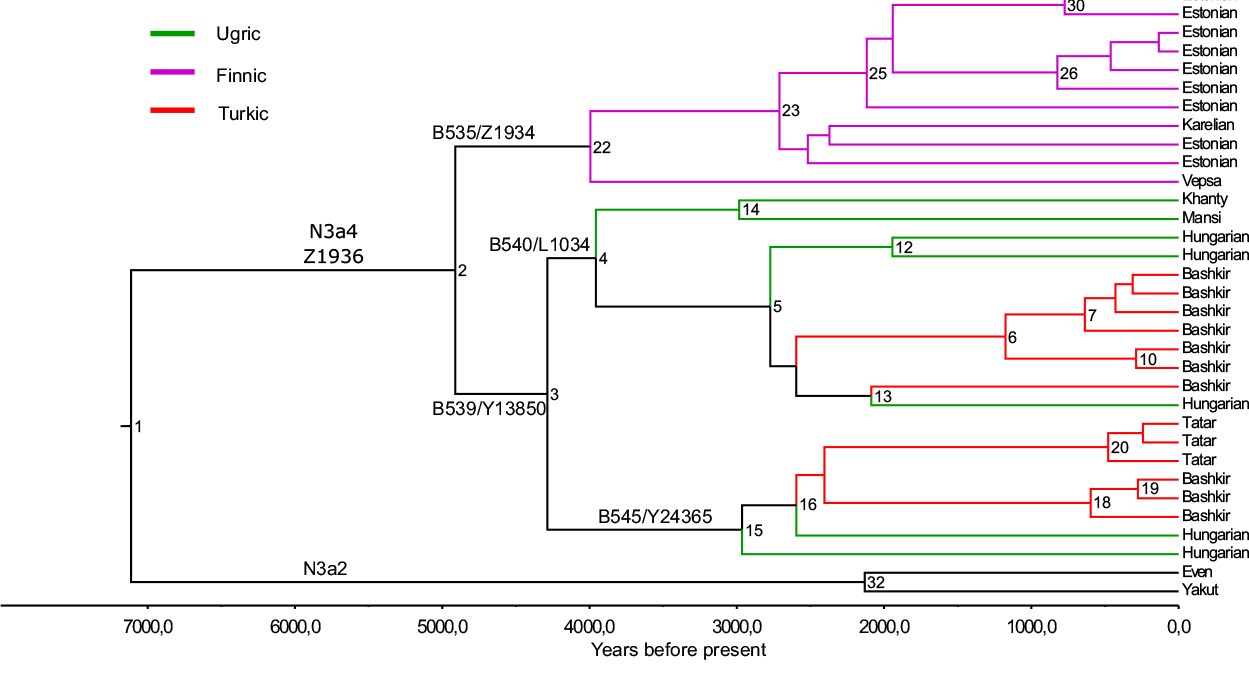
haplogroup N3a4 was reconstructed with BEAST v.1.7.5 software package.
Archaeogenetic studies based on mtDNA haplotypes have shown that ancient Hungarians were relatively close to contemporary Bashkirs who are a Turkic speaking population residing in the Volga-Ural region. Another study reported excessive identical-by-descent (IBD) genomic segments shared between the Ob-Ugric speaking Khantys and Bashkirs but a moderate IBD sharing between Turkic speaking Tatars and their neighbours including Bashkirs.
Phylogenetic tree of hg N3a4 has two main sub-clades defined by markers B535 and B539 that diverged around 4.9 kya (95% confidence interval [CI] = 3.7–6.3 kya). Inner sub-clades of N3a4-B539 (defined by markers B540 and B545) split 4.2 kya (95% CI = 3.0–5.6 kya). (…) The phylogenetic tree reveals that all five Hungarian samples belong to N3a4-B539 sub-clade that they share with Ob-Ugric speaking Khanty and Mansi, and Turkic speaking Bashkirs and Tatars from the Volga-Ural region. Hungarian and Bashkir chrY lineages belong to both sub-clades of N3a4-B539.
Modern distribution of the “Ugric N1c”
To test the presence and proportions of hg N3a4 lineages in a more comprehensive sample set and with a higher phylogenetic resolution level compared to earlier studies, we analysed the genotyping data of about 5000 Eurasian individuals, including West Siberian Mansi and Khanty who are linguistically closest to Hungarians
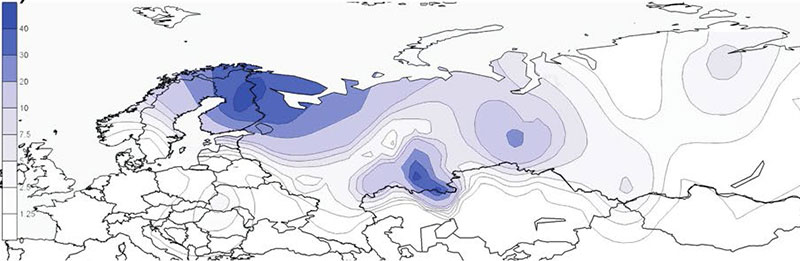
There is a clear difference in geographic distribution patterns of these two hg N3a4 sub-clades. Hg N3a4-B535 (Fig. 3b) is common mostly among Finnic (Finns, Karelians, Vepsas, Estonians) and Saami speaking populations in North eastern Europe. The highest frequency is detected in Finns (~44%) but it also reaches up to 32% in Vepsas and around 20% in Karelians, Saamis and North Russians. The latter are known to have changed their language or to be an admixed population with reported similar genetic composition to their Finnic speaking neighbors. The frequency of N3a4-B535 rapidly decreases towards south to around 5% in Estonians, being almost absent in Latvians (1%) and not found among Lithuanians. Towards east its frequency is from 1–9% among Eastern European Russians and populations of the Volga-Ural region such as Komis, Mordvins and Chuvashes (…)
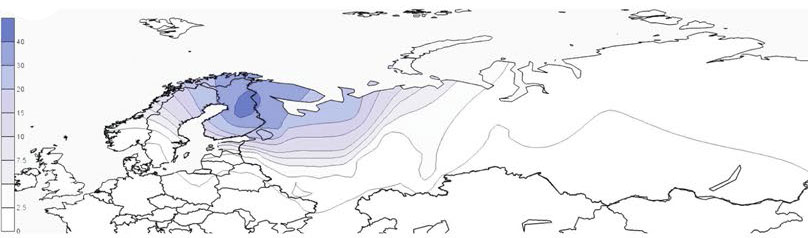
Hg N3a4-B539, on the other hand, is prevalent among Turkic speaking Bashkirs and also found in Tatars but is entirely missing from other populations of the Volga-Ural region such as Uralic speaking Udmurts, Maris, Komis and Mordvins, and in Northeast Europe, where instead N3a4-B535 lineages are frequent. Besides Bashkirs and Tatars in Volga-Ural region, N3a4-B539 is substantially represented in West Siberia among Ugric speaking Mansis and Khantys. Among Hungarians, however, N3a4-B539 has a subtle frequency of 1–4%.
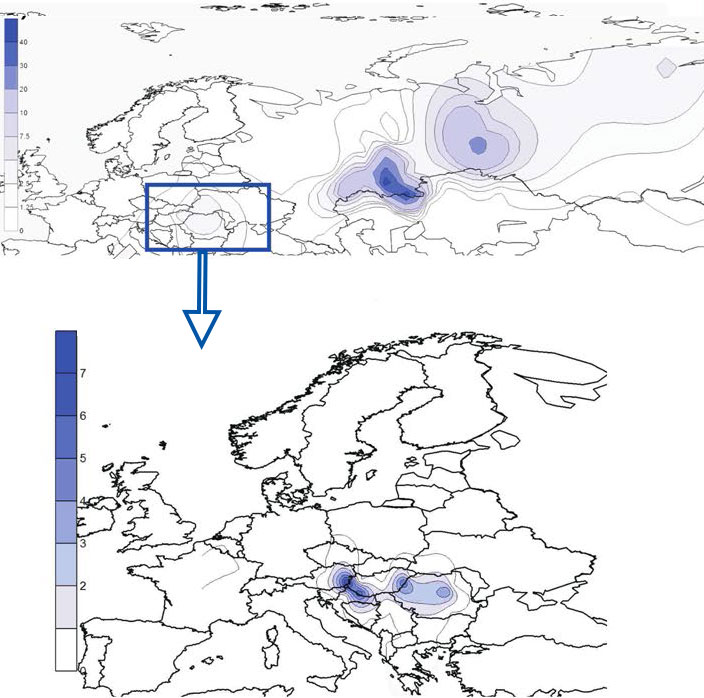
The battle to appropriate N1c-L392
So, basically, the team of Kristiina Tambets is arguing that N1c-VL29 expanded Finnic to the East Baltic (hence from a common Finno-Mordvinic dialect splitting ca. 600 BC on?) because, you know, apparently the agreed separation of known Uralic dialects from ca. 2000 BC, and their Bronze Age presence around the Baltic, is not valid when you follow haplogroups instead of languages or archaeology.
But now this other group of Tambets (co-author of this paper) considers that hg. N1c-Z1936 – which is probably behind the N1c-L392 samples from Lovozero Ware in the Kola Peninsula – represent either the True Uralic-speaking Palaeo-Arctic peoples, or else merely Ugric-speaking peoples which happened to expand to Fennoscandia but left no trace of their language…
To accept this identification you only have to NOT ask why:
- N1c is first found in ancient cultures close to Lake Baikal.
- N1c-L392 appears in ancient East Asian populations speaking completely different languages, with Altaic and Uralic being just some among many Palaeo-Siberian populations where the haplogroup will pop up.
- Turkic populations like Bashkirs and Tatars (who expanded to the Volga through the southern Urals before the expansion of Hungarians) show a shared distribution of the B539 haplotype with Hungarians.
- The phylogenetic tree and areas of N1c-L392 expansions don’t make any sense in light of the known linguistic and cultural expansions of Uralic-speaking peoples.
In fact, the Hungarian research group of Neparáczki – publishing the recent paper on Hungarian Conquerors – was apparently looking for a connection with Turkic peoples to support some traditional Turanian myths, and they found it in some scattered R1a-Z93 samples which supposedly connect Hungarian Conquerors to Huns (?), instead of looking for this closer link through N1c-Z1936 (especially haplotype B539)…
Also, is it me or are there two opposed trends with completely different interpretations among researchers publishing papers about hg. N1c: one systematically arguing for Altaic origins, and another for Uralic ones?
If somebody sees some complex reasoning behind the discussions of all these recent papers, beyond the simplest “let’s follow N for Uralic/Altaic”, feel free to comment below. Just so I can understand what I might be doing wrong in assessing Neolithic and Bronze Age migrations in linguistics and archaeology with help of ancient haplogroups coupled with ancestral components, but these researchers are doing right by playing with obsessive ideas born out of the 2000s coupled with phylogenetic trees and maps of modern haplogroup distributions…
This is probably going to be this blog’s most used image in 2019:

Related
- Baltic Finns in the Bronze Age, of hg. R1a-Z283 and Corded Ware ancestry
- Uralic speakers formed clines of Corded Ware ancestry with WHG:ANE populations
- The cradle of Russians, an obvious Finno-Volgaic genetic hotspot
- Magyar tribes brought R1a-Z645, I2a-L621, and N1a-L392(xB197) lineages to the Carpathian Basin
- R1a-Z280 and R1a-Z93 shared by ancient Finno-Ugric populations; N1c-Tat expanded with Micro-Altaic
- The complex origin of Samoyedic-speaking populations
- Corded Ware—Uralic (IV): Hg R1a and N in Finno-Ugric and Samoyedic expansions
- Corded Ware—Uralic (III): “Siberian ancestry” and Ugric-Samoyedic expansions
- Corded Ware—Uralic (II): Finno-Permic and the expansion of N-L392/Siberian ancestry
- The traditional multilingualism of Siberian populations
- Corded Ware—Uralic (I): Differences and similarities with Yamna
- Haplogroup R1a and CWC ancestry predominate in Fennic, Ugric, and Samoyedic groups