Short report on advances in Genomics, and on the Reich Lab:
Some interesting details:
- The Lab is impressive. I would never dream of having something like this at our university. I am really jealous of that working environment.
- They are currently working on population transformations in Italy; I hope we can have at last Italic and Etruscan samples.
- It is always worth it to repeat that we are all the source of multiple admixture events, many of them quite recent; and I liked the Star Wars simile.
- Also, some names hinting at potential new samples?? Zajo-I, Chanchan, Gurulde?, Володарка (Ukraine – medieval?), Autodrom, Облевка, Кресты, Кудуксай (Ural region, palaeo-metal?), Золкут, etc.

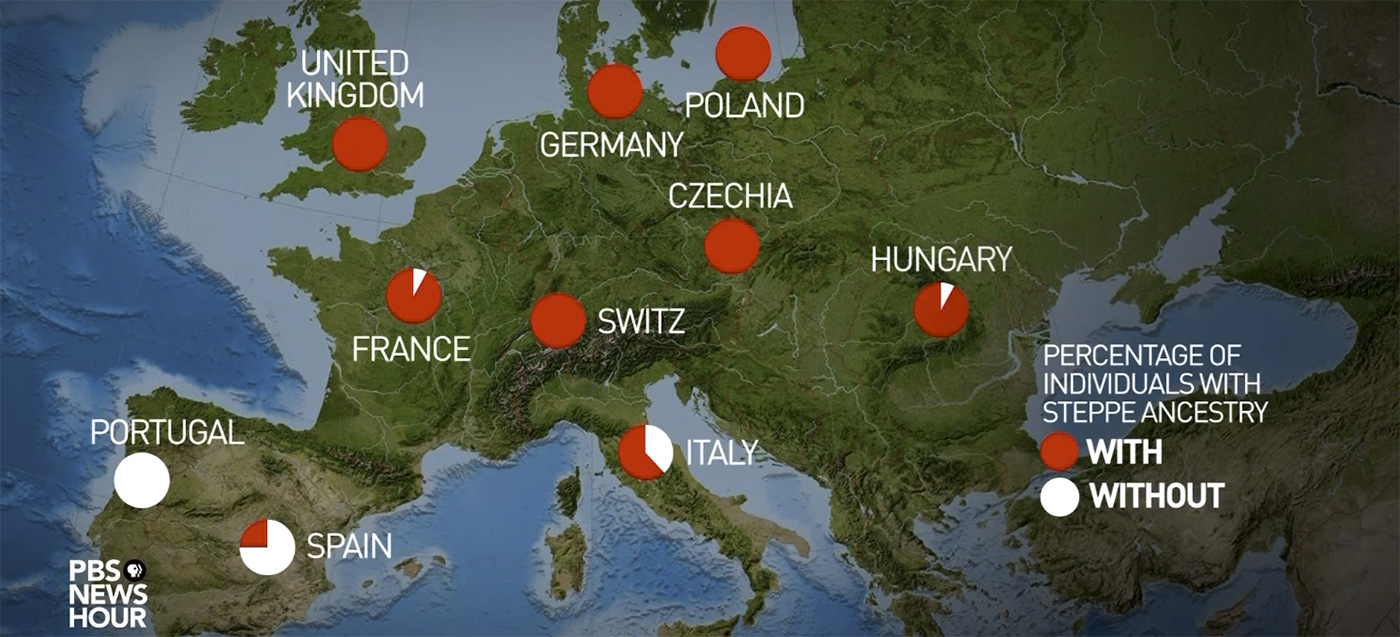
On the bad aspect, they keep repeating the same “steppe ancestry” meme (in the featured image above, or the one below). I know this is the news report (i.e. science communication), not exactly the Reich Lab, but these maps didn’t appear out of the blue.
Interesting for future interpretations is the whiteboard behind David Reich’s back (apparently they like to keep relevant information on whiteboards…):
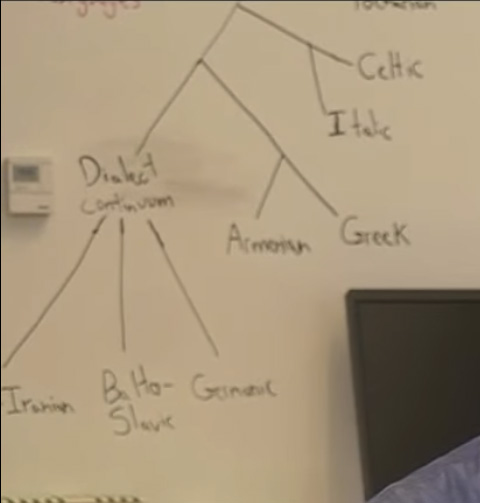
It seems that while the Copenhagen group will still be bound (see here) by the Gimbutas/Kristiansen starting point, the Reich Lab will remain bound by Anthony’s selection of Ringe’s (2002) glottochronological model, and they will try to make genomic data fit in with it.
In fact, the whiteboard doesn’t even include Ringe’s link of Germanic with Italo-Celtic, which could maybe hint at Anthony’s recent change of heart? (i.e. Yamna Hungary -> Corded Ware). That would mean still less Linguistics (if glottochronology can be called that), and more Archaeology…
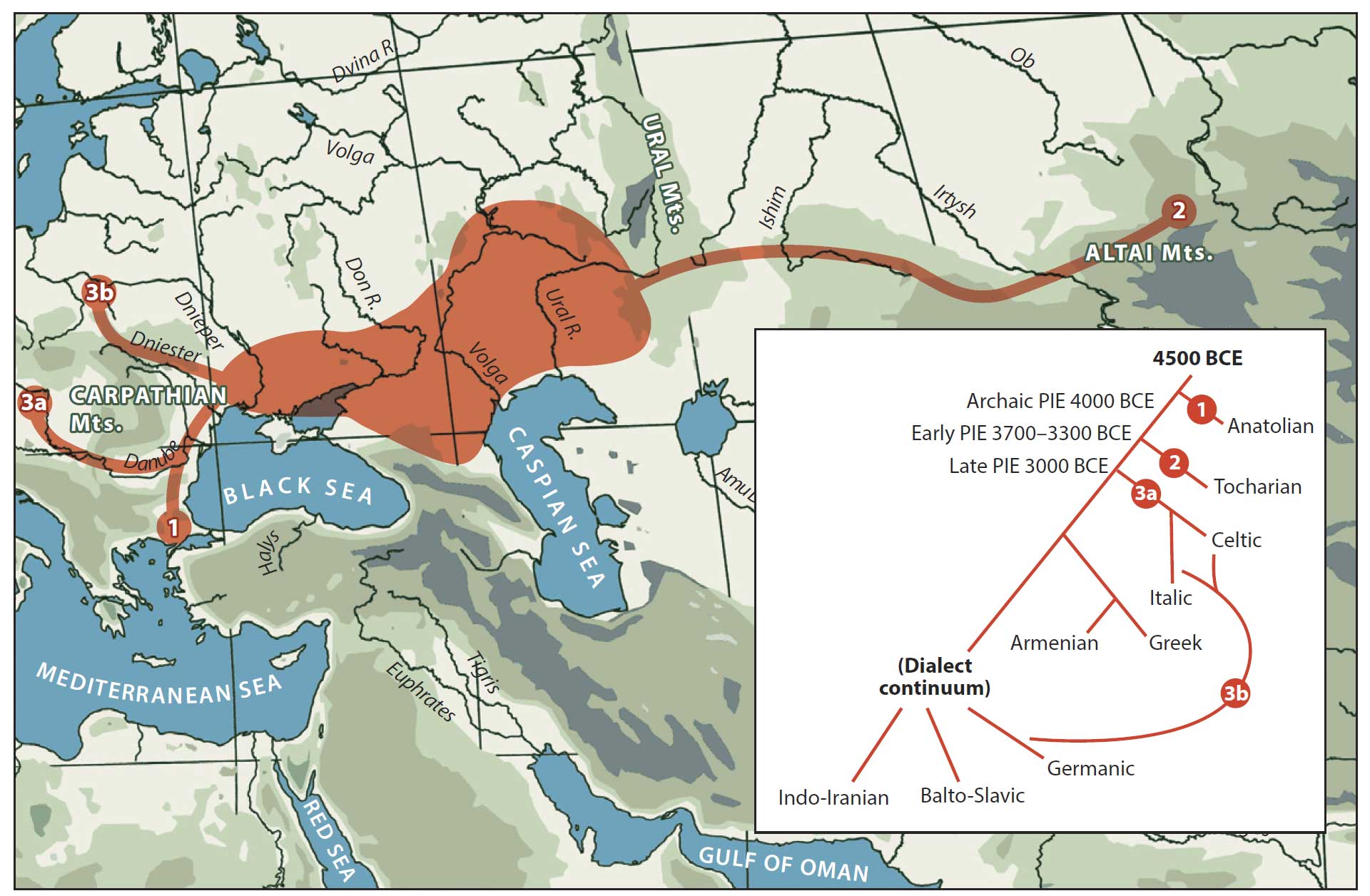
I don’t know why university labs need to do this: To select the linguistic model preferred by a single archaeologist, which happens to be the lead archaeologist of the group, and then try to make genetic data agree again and again with that model. I guess it is a strategic question, and has to do with granting continued contacts with archaeological sites, and access to samples from them?
I understand none of them will try to learn ancient languages, too much work probably. But, wouldn’t it have been more scientifish, at least, to depart from, say, three or four reasonable potential linguistic models (that is, from Indo-Europeanists), and from there discuss the best potential fits for the current genomic data in each paper?
This is, for example, how the Heyd (archaeologist) + German/Spanish Indo-Europeanist schools would look like:
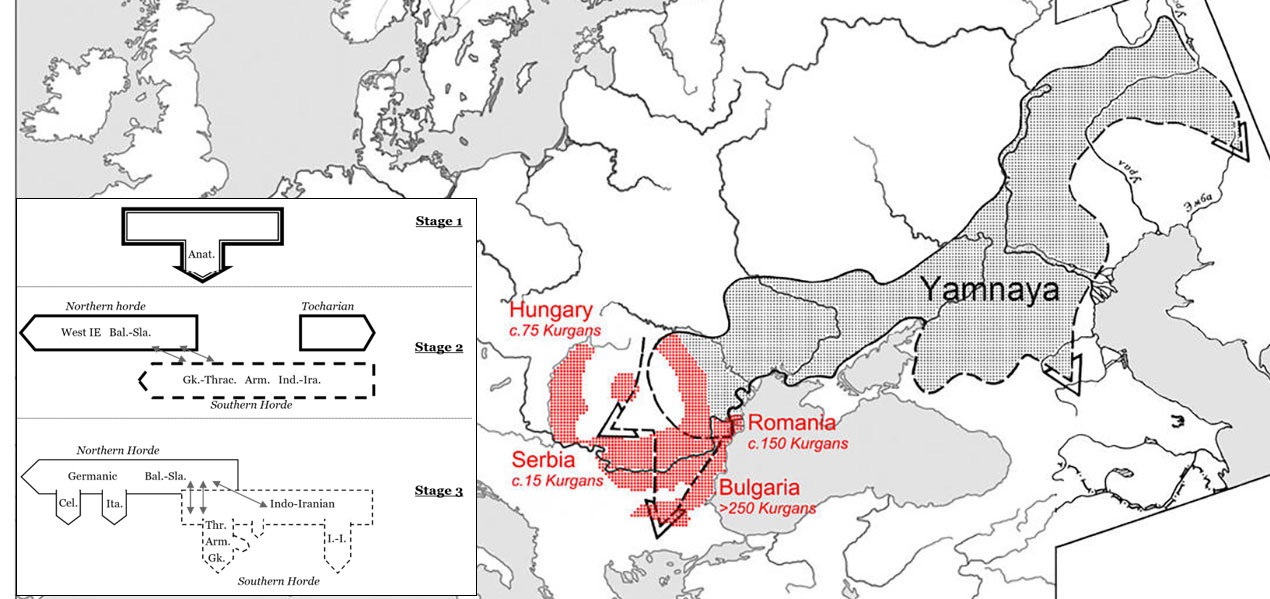
Wouldn’t you say it could have fitted the statistical and Y-DNA data seamlessly, in contrast to Gimbutas/Trager (i.e. Kristiansen today), or to Anthony/Ringe?
NOTE. I would say the mainstream German school follows Meid’s (1975) three-stage theory coupled with Dunkel’s (e.g. 1997) nomenclature. The Spanish school follows Adrados, who has repeated ad nauseam that he was the first to mention the three-stage theory in conferences and papers previous to and coincident with Meid’s proposal (see his latest JIES article, a paper available in Scribd). In any case, Spanish and German scholars have been working hand in hand in accepting and developing a general linguistic model similar to the one above.
Archaeological theories like those of Heyd or Mallory for Yamna and Bell Beaker (in contrast to Kristiansen or Anthony), and Prescott and Walderhaug for Bell Beaker and Germanic (contrasting with Kristiansen and Iversen) are compatible with this German/Spanish model.
The French school is non-existent on the homeland matter, Italian scholars seem to be behind even in the description of Anatolian as archaic (probably related to the general wish to have Latin as derived from Vergil’s Troy), Russian scholars are still working with Nostratic and Mesolithic expansions, and Leiden, as the leading IE publisher worldwide today, is full of very different ‘divos’, each with his own pet theory (some obviously agreeing with the German/Spanish model; and especially interesting is that some of them are strong supporters of an Indo-Uralic proto-language).
The English-speaking world, on the other hand, has seen the most varied models being either proposed or translated into its language, with the most popular ones being those publicized by archaeologists (Winfred P. Lehmann being one of the noteworthy exceptions), which may explain why for some people (archaeologists or geneticists) linguistics seems more like a game. It is to be assumed that these same people haven’t taken a look at the dozens of genetic papers published to date – and hundreds of archaeological papers using a bit of linguistics to support their models – , and how wrong they have all been in their interpretations, or else they would realize that genomics does (sadly) not really look like a serious discipline at all right now among most linguists, and among many archaeologists either…
Thus, instead of comparing the main theories on Proto-Indo-European (i.e. linguistics->archaeology->genetics), which would have offered the most stable framework to assess potential prehistoric ethnolinguistic identifications, they keep using a single, simplistic language tree liked by an archaeologist, and trying to fit genetic data to it, while also adapting archaeology to genetics, i.e. genetics->archaeology->linguistics; which, as you can imagine, is not going to convince any linguist.
Especially disappointing is that the world’s leading genetic lab still relies on a marginal proposal based on glottochronology, the homeopathy of linguistics… At least in that regard everyone should know better by now.
Also, they keep interacting with the wrong audience: instead of trying to engage linguists into the real homeland and dialectal quest, to keep Genomics a serious discipline among academics, they tend to discuss with politically- or racially-motivated people, which is probably also in line with strategic decisions.
In the example below, we see the main author of their recent paper on Indo-Iranian migrations seeking once again interaction, this time through “news” promoted by Hindu nationalist bigots, so that – even if that makes them look more neutral in the eyes of those who may allow access to Indian samples – , in the end, we see in genomics a fictitious revival of the “AIT vs. OIT debate” dead long ago in linguistics and archaeology (anywhere but in India).
There has been a lot of news about the discovery of a chariot and the burial of an 'elite warrior' from Sanauli, India recently. Based on the archeological context, and the wheel/chariot vocabulary used as a critical piece of evidence for the spread of Indo European, 1/n pic.twitter.com/KtCvc1iJEY
— Vagheesh Narasimhan (@vagheesh) June 6, 2018
Pretty disappointing to see these trends; so much effort and time invested in futile discussions and infinitely reworked doomed glottochronological or 19th-century models, when it is the fine-scale population structure of expanding Yamna peoples what we should be discussing now, and thus Late PIE dialectalisation with offshoots Afanasevo, East Bell Beaker, Balkan Bronze Age, and Sintashta/Potapovka; as well as Corded Ware evolution in Uralic-speaking territory.
EDIT (7 JUN 2018): Some parts of the text have been corrected or slightly modified.
Related:
- David Reich on social inequality and Yamna expansion with few Y-DNA subclades
- David Reich on the influence of ancient DNA on Archaeology and Linguistics
- East Bell Beakers, an in situ admixture of Yamna settlers and GAC-like groups in Hungary
- Immigration and transhumance in the Early Bronze Age Carpathian Basin
- The Caucasus a genetic and cultural barrier; Yamna dominated by R1b-M269; Yamna settlers in Hungary cluster with Yamna
- Brexit forces relocation of one of today’s main Yamna research projects to Finland
- Olalde et al. and Mathieson et al. (Nature 2018): R1b-L23 dominates Bell Beaker and Yamna, R1a-M417 resurges in East-Central Europe during the Bronze Age
- Consequences of Damgaard et al. 2018 (III): Proto-Finno-Ugric & Proto-Indo-Iranian in the North Caspian region
- Consequences of Damgaard et al. 2018 (II): The late Khvalynsk migration waves with R1b-L23 lineages
- North Pontic steppe Eneolithic cultures, and an alternative Indo-Slavonic model
- The concept of “Outlier” in Human Ancestry (III): Late Neolithic samples from the Baltic region and origins of the Corded Ware culture