The awaited, open access paper on Asian migrations is out: The Genomic Formation of South and Central Asia, by Narasimhan et al. bioRxiv (2018).
Abstract:
The genetic formation of Central and South Asian populations has been unclear because of an absence of ancient DNA. To address this gap, we generated genome-wide data from 362 ancient individuals, including the first from eastern Iran, Turan (Uzbekistan, Turkmenistan, and Tajikistan), Bronze Age Kazakhstan, and South Asia. Our data reveal a complex set of genetic sources that ultimately combined to form the ancestry of South Asians today. We document a southward spread of genetic ancestry from the Eurasian Steppe, correlating with the archaeologically known expansion of pastoralist sites from the Steppe to Turan in the Middle Bronze Age (2300-1500 BCE). These Steppe communities mixed genetically with peoples of the Bactria Margiana Archaeological Complex (BMAC) whom they encountered in Turan (primarily descendants of earlier agriculturalists of Iran), but there is no evidence that the main BMAC population contributed genetically to later South Asians. Instead, Steppe communities integrated farther south throughout the 2nd millennium BCE, and we show that they mixed with a more southern population that we document at multiple sites as outlier individuals exhibiting a distinctive mixture of ancestry related to Iranian agriculturalists and South Asian hunter-gathers. We call this group Indus Periphery because they were found at sites in cultural contact with the Indus Valley Civilization (IVC) and along its northern fringe, and also because they were genetically similar to post-IVC groups in the Swat Valley of Pakistan. By co-analyzing ancient DNA and genomic data from diverse present-day South Asians, we show that Indus Periphery-related people are the single most important source of ancestry in South Asia — consistent with the idea that the Indus Periphery individuals are providing us with the first direct look at the ancestry of peoples of the IVC — and we develop a model for the formation of present-day South Asians in terms of the temporally and geographically proximate sources of Indus Periphery-related, Steppe, and local South Asian hunter-gatherer-related ancestry. Our results show how ancestry from the Steppe genetically linked Europe and South Asia in the Bronze Age, and identifies the populations that almost certainly were responsible for spreading Indo-European languages across much of Eurasia.
NOTE. The supplementary material seems to be full of errors right now, because it lists as R1b-M269 (and further subclades) samples that have been previously expressly said were xM269, so we will have to wait to see if there are big surprises here. So, for example, samples from Mal’ta (M269), Iron Gates (M269 and L51), and Latvia Mesolithic (L51), a Deriivka sample from 5230 BC (M269), Armenia_EBA (Z2103)…Also, the sample from Yuzhnyy Oleni Ostrov is R1a-M417 now.
EDIT (1 APR 2018): The main author has confirmed on Twitter that they have used a new Y Chr caller that calls haplogroups given the data provided, and depending on the coverage tried to provide a call to the lowest branch of the tree possible, so there are obviously a lot of mistakes – not just in the subclades of R. A revision of the paper is on its way, and soon more people will be able to work with the actual samples, since they say they are releasing them.
Nevertheless, since it is subclades (and not haplogroups) the apparent source of gross errors, for the moment it seems we can say with a great degree of confidence that:
- New samples of East Yamna / Poltavka are of haplogroup R1b-L23.
- Afanasevo is confirmed to be dominated by R1b-M269.
- Sintashta, as I predicted could happen, shows a mixed R1b-L23/ R1a-Z645 society, compatible with my model of continuity of Proto-Indo-Iranian in the East Yamna admixture with late Corded Ware immigrants.
With lesser confidence in precise subclades, we find that:
- A sample from Hajji Firuz in Iran
ca. 5650 BC, of subclade R1b-Z2103, may confirm Mesolithic R1b-M269 lineages from the Caucasus as the source of CHG ancestry to Khvalynsk/Yamna, and be thus the reason why Reich wrote about a potential PIE homeland south of the Caucasus . (EDIT 11 APR 2018) The sample shows steppe ancestry, therefore the date is most likely incorrect, and a new radiocarbon dating is due. It is still interesting – depending on the precise subclade – for its potential relationship with IE migrations into the area. - New samples of East Yamna / Poltavka are of haplogroup R1b-Z2103.
- Afanasevo migrants are mainly of haplogroup R1b-Z2103.
- The Darra-e Kur sample, ca. 2655, of haplogroup R1b-L151, without a clear cultural adscription, may be the expected sign of Afanasevo migrants (Pre-Proto-Tocharian speakers) expanding a Northern Indo-European (in contrast with a Southern or Graeco-Aryan) dialect, in a region closely linked with the later desert mummies in the Tarim Basin. Its early presence there would speak in favour of a migration through the Inner Asian Mountain Corridor previous to the one caused by Andronovo migrants.
- Sintashta shows a mixed R1b-Z2103 / R1a-Z93 society.
- Later Indo-Iranian migrations are apparently dominated by R1a-Z2123, an early subclade of R1a-Z93, also found in Srubna.
- R1b is also seen later in BMAC (ca. 1487 BC), although its subclade is not given.
- There is also a sample of R1a-Z283 subclade in the eastern steppe (ca. 1600 BC). What may be interesting about it is that it could mark one of the subclades not responsible for the expansion of Balto-Slavic (or responsible for it with the expansion of Srubna, for those who support an Indo-Slavonic branch related Sintashta-Potapovka).
- A sample of R1b-U106 subclade is found in Loebanr_IA ca. 950 BC, which – together with the sample of Darra-e Kur – is compatible with the presence of L51 in Yamna.
NOTE. Errors in haplogroups of previously published samples make every subclade of new samples from the supplementary table questionable, but all new samples (safe for the Darra_i_Kur one) were analysed and probably reported by the Reich Lab, and at least upper subclades in each haplogroup tree seem mostly coherent with what was expected. Also, the contribution of Iranian Farmer related (a population in turn contributing to Hajji Firuz) to Khvalynsk in their sketch of the genetic history may be a sign of the association of R1b-M269 lineages with CHG ancestry, although previous data on precise R1b subclades in the region contradict this. (EDIT 11 APR 2018) The sample of Hajji Firuz is most likely much younger than the published date, hence its younger subclade may be correct. No revision or comment on this matter has been published, though.
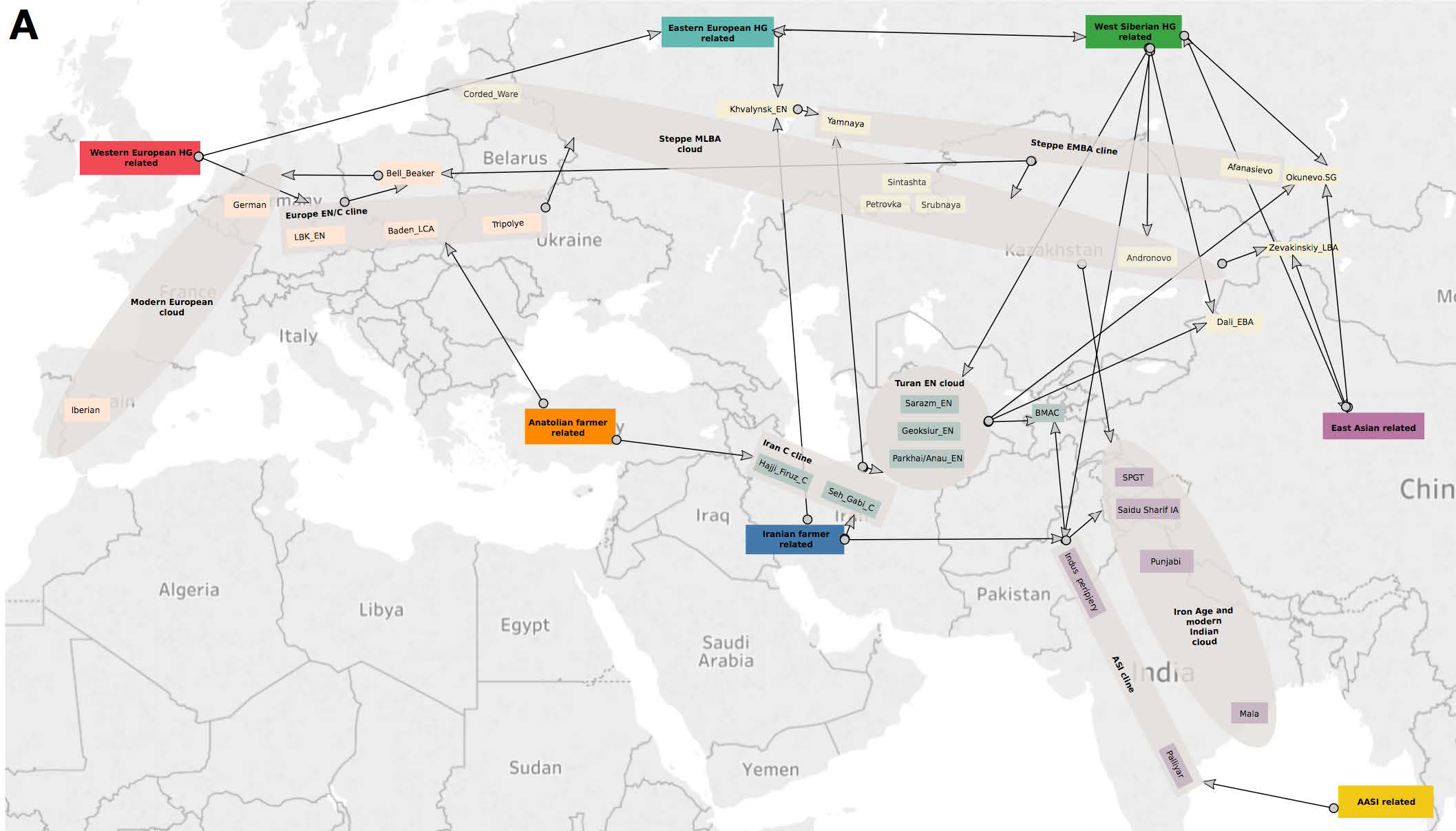
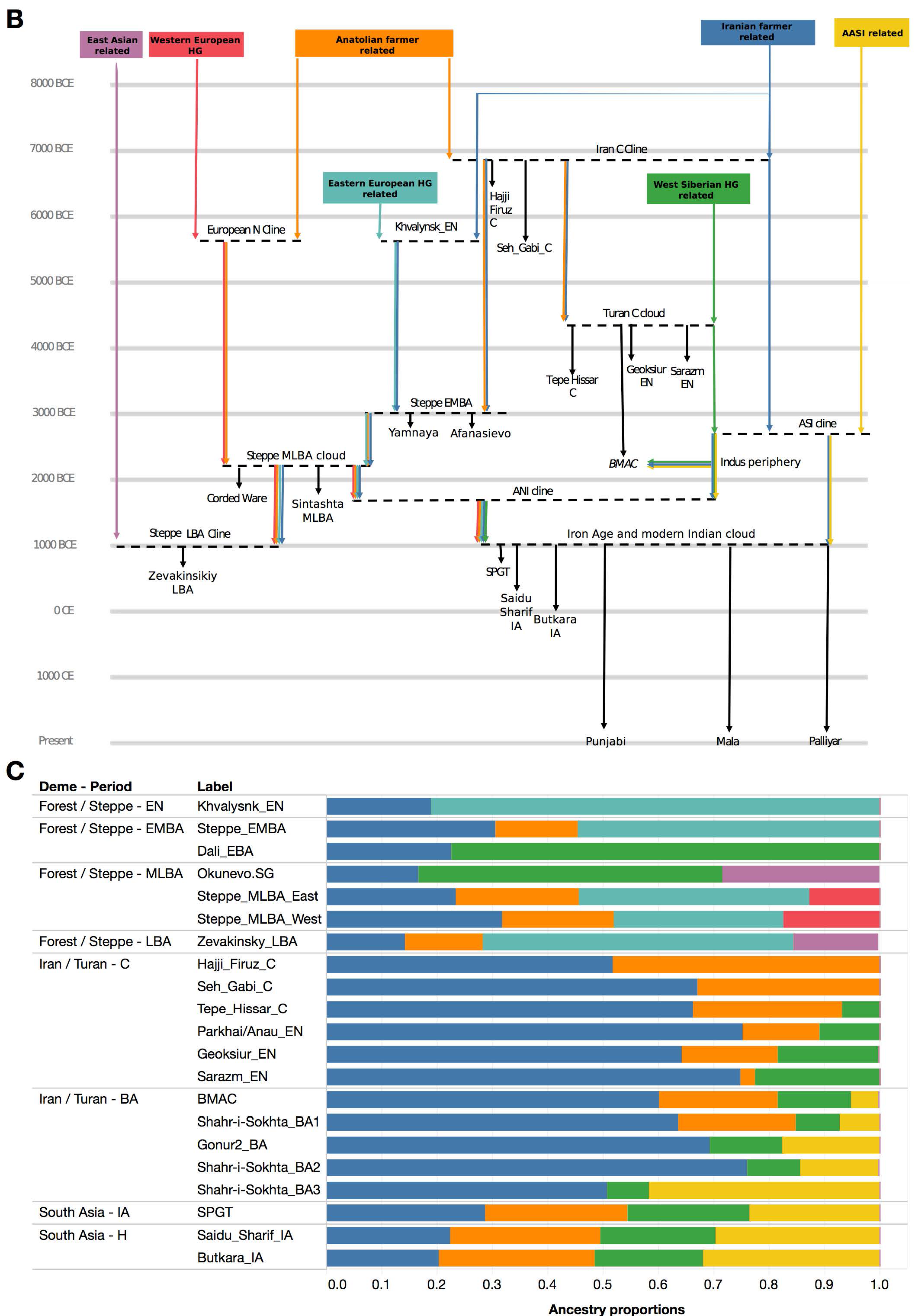
Also, it seems that the Corded Ware culture appears now irrelevant for Late Proto-Indo-European migrations. Observe:
- The graphic model above, with a clear distinction of a “Steppe EMBA cline” (associated with Late Proto-Indo-European) expanding into Afanasevo, Bell Beaker, and into the eastern part of a “Steppe MLBA cloud” including CWC-Sintashta-Andronovo;
- the featured image of this post, showing a Yamna -> Corded Ware expansion through the Carpathian Basin as the model suggested recently by Anthony;
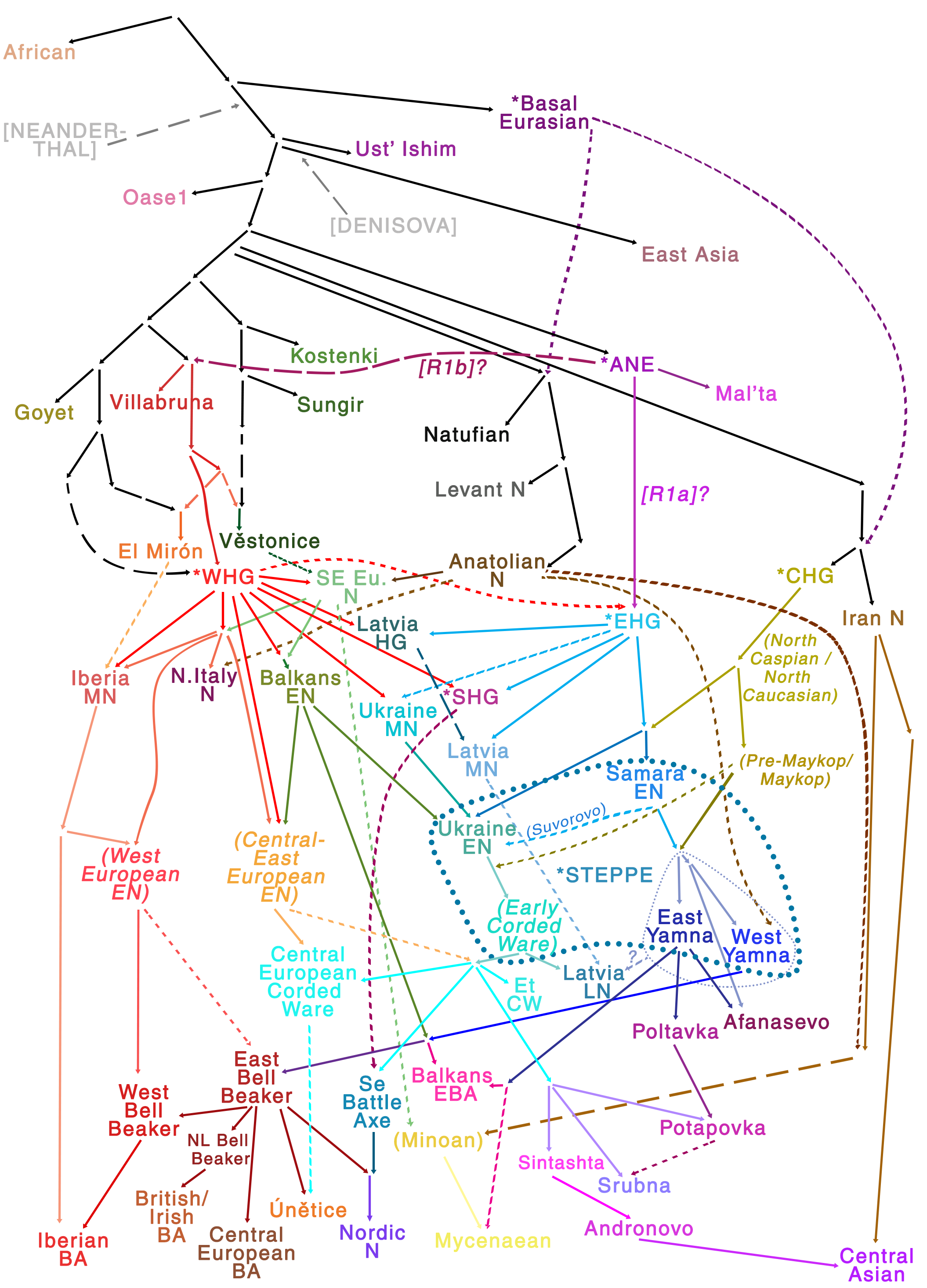
- and the schematic genetic model below, similar to my previous tentative sketch of the genetic history of West Eurasia.
{kind=link}
In the text, a consistent terminology of Yamnaya or Yamnaya-related Steppe pastoralists, discarding the relevance of previous migrations from the North Pontic steppe in spreading Late Indo-European:
Our results also shed light on the question of the origins of the subset of Indo-European languages spoken in India and Europe (45). It is striking that the great majority of Indo-European speakers today living in both Europe and South Asia harbor large fractions of ancestry related to Yamnaya Steppe pastoralists (corresponding genetically to the Steppe_EMBA cluster), suggesting that “Late Proto-Indo-European”—the language ancestral to all modern Indo- European languages—was the language of the Yamnaya (46). While ancient DNA studies have documented westward movements of peoples from the Steppe that plausibly spread this ancestry to Europe (5, 31), there has not been ancient DNA evidence of the chain 488 of transmission to South Asia. Our documentation of a large-scale genetic pressure from Steppe_MLBA groups in the 2nd millennium BCE provides a prime candidate, a finding that is consistent with archaeological evidence of connections between material culture in the Kazakh middle-to-late Bronze Age Steppe and early Vedic culture in India (46).
EDIT (1 APR 2018): I corrected this text and the word ‘official’ in the title, because more than rejecting the role of Corded Ware migrants in expanding Late PIE, they actually seem to keep considering Corded Ware migrants as continuing the western Yamna expansion in the Carpathian Basin, so no big ‘official’ change or retraction in this paper, just subtle movements out of their previous model.
NOTE. If they correct the haplogroups soon, I will update the information in this post. Unless there is a big surprise that merits a new one, of course.
EDIT (1 APR 2018): Multiple minor edits to the original post.
EDIT (2 APR 2018): While I and other simple-minded people were only looking to confirm our previous theories using Y-DNA haplogroups, and are content with wildly speculating over the consequences if some of those strange (probably wrong) ones were true, intelligent people are using their time for something useful, interpreting the results of the investigation as described in the paper, to offer a clearer picture of Indo-Iranian migrations for everyone:
- How We, The Indians, Came to Be, by Tony Joseph.
- Aryan migration: Everything you need to know about the new study on Indian genetics, by Rohan Venkataramakrishnan.
- The Maturation Of The South Asian Genetic Landscape, by Razib Khan.
Visit the beautiful interactive map with samples: with their location, PCA, ADMIXTURE and haplogroups (still with those originally given): https://public.tableau.com/profile/vagheesh#!/vizhome/TheGenomicFormationofSouthandCentralAsia/Fig_1
Featured image, from the article: “A Tale of Two Subcontinents. The prehistory of South Asia and Europe are parallel in both being impacted by two successive spreads, the first from the Near East after 7000 BCE bringing agriculturalists who mixed with local hunter-gatherers, and the second from the Steppe after 3000 BCE bringing people who spoke Indo-European languages and who mixed with those they encountered during their migratory movement. Mixtures of these mixed populations then produced the rough clines of ancestry present in both South Asia and in Europe today (albeit with more variable proportions of local hunter-gatherer-related ancestry in Europe than in India), which are (imperfectly) correlated to geography. The plot shows in contour lines the time of the expansion of Near Eastern agriculture. Human movements and mixtures, which also plausibly contributed to the spread of languages, are shown with arrows.”
Related:
- Y-DNA haplogroup R1b-Z2103 in Proto-Indo-Iranians?
- The Indus Valley Civilisation in genetics – the Harappan Rakhigarhi project
- Mitogenomes show ancient human migrations to and through North-East India not of males exclusively
- Consequences of O&M 2018 (II): The unsolved nature of Suvorovo-Novodanilovka chiefs, and the route of Proto-Anatolian expansion
- The Aryan migration debate, the Out of India models, and the modern “indigenous Indo-Aryan” sectarianism
- Consequences of O&M 2018 (I): The latest West Yamna “outlier”
- Olalde et al. and Mathieson et al. (Nature 2018): R1b-L23 dominates Bell Beaker and Yamna, R1a-M417 resurges in East-Central Europe during the Bronze Age
- Reactionary views on new Yamna and Bell Beaker data, and the newest IECWT model
- The Indo-European demic diffusion model, and the “R1b – Indo-European” association
- The concept of “Outlier” in Human Ancestry (III): Late Neolithic samples from the Baltic region and origins of the Corded Ware culture
- New Ukraine Eneolithic sample from late Sredni Stog, near homeland of the Corded Ware culture
- Indo-European and Central Asian admixture in Indian population, dependent on ethnolinguistic and geodemographic divisions
- Germanic–Balto-Slavic and Satem (‘Indo-Slavonic’) dialect revisionism by amateur geneticists, or why R1a lineages *must* have spoken Proto-Indo-European