Given my reduced free time in these months, I have decided to keep updating the text on Indo-European and Uralic migrations and/or this blog, simultaneously or alternatively, to make the most out of the time I can dedicate to this. I will add the different ‘A Song of Sheep and Horses (ASoSaH) reread’ posts to the original post announcing the books. I would be especially interested in comments and corrections to the book chapters rather than the posts, but any comments are welcome (including in the forum, where comments are more likely to stick).
This is mainly a reread of iv.2. Indo-Anatolians and vi.1. Disintegrating Indo-Europeans.
Indo-Anatolians and Late Indo-Europeans
I have often written about R1b-L23 as the majority haplogroup among Late Proto-Indo-Europeans (see my predictions for 2018 and my summary of 2018), but always expected other haplogroups to pop up somewhere along the way, in Khvalynsk, in Repin, in Yamna, and in Bell Beakers (see e.g. the post on common fallacies of R1a/IE-fans).
Luckily enough – for those of us who want precise answers to our previous infinite models of Indo-European language expansions (viz. GAC-associated expansion, IE-speaking Old Europe, Anatolian homeland, Iran homeland, Maykop as Proto-Anatolian, Palaeolithic Continuity Theory, Celtic in the Atlantic façade, etc.) – the situation has been more clear-cut than expected: it turns out that, especially during population expansions, acute Y-chromosome bottlenecks were very common in the past, at least until the Iron Age.
Khvalynsk and Repin-Yamna expansions were no different, and that seems quite natural in hindsight, given the strong familial ties and aversion to foreigners proper of the Late Proto-Indo-European society and culture – probably not really that different from other contemporary societies, like the neighbouring Late Proto-Uralic or Trypillian ones.
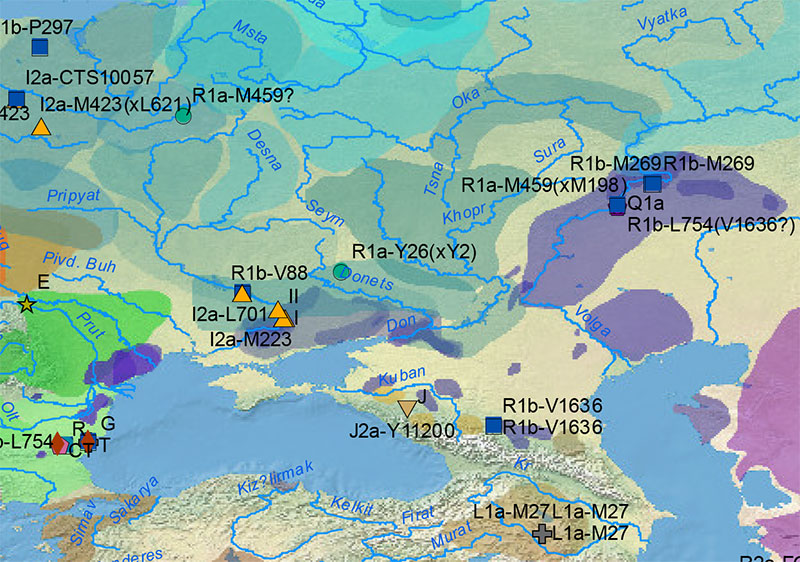
Y-DNA haplogroups
During the expansion of early Khvalynsk, the most likely Indo-Anatolian culture, the society of the Don-Volga area was probably made up of different lineages including R1b-V1636, R1b-M269, R1a-YP1272, Q1a-M25, and I2a-L699 (and possibly some R1b-V88?), a variability possibly greater than that of the contemporary north Pontic area, probably a sign of this region being a sink of different east and west migrations from steppe and forest areas.
During its expansion, the Khvalynsk society saw its haplogroup variability reduced, as evidenced by the succeeding expansive Repin culture:
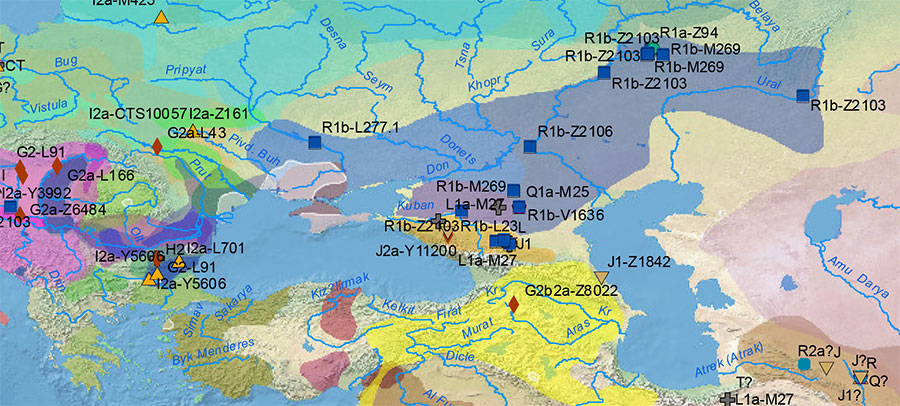
Afanasevo, representing Pre-Tocharian (the earliest Late PIE dialect to branch off), expanded with R1b-L23 – especially R1b-Z2103 – lineages, while early Yamna expanded with R1b-L23 and I2a-L699 lineages, which suggests that these are the main haplogroups that survived the Y-DNA bottleneck undergone during the Khvalynsk expansion, and especially later during the late Repin expansion. Nevertheless, other old haplogroups might still pop up during the Repin and early Yamna period, such as the R1b-V1636 sample from Yamna in the Northern Caucasus.
It is still unclear if R1b-L23 sister clade R1b-PF7562 (formed ca. 4400 BC, TMRCA ca. 3400 BC), prevalent among modern Albanians, expanded with Yamna migrants, or if it was part of an earlier expansion of R1b-M269 into the Balkans, and represent thus Indo-Anatolian speakers who later hitchhiked the expansion of the Late PIE language from the north or west Pontic area. The early TMRCA seems to suggest an association with Repin (and therefore Yamna), rather than later movements in the Balkans.
‘Yamnaya’ or ‘steppe’ ancestry?
After the early years when population genetics relied mainly on modern Y-DNA haplogroups, geneticists and amateurs have been recently playing around with testing “ancestry percentages”, based on newly developed free statistical tools, which offer obviously just one among many types of data to achieve a proper interpretation of the past.
Today we have quite a lot Y-DNA haplogroups reported for ancient samples of more recent prehistoric periods, and they seem to offer (at least since the 2015 papers, but more evidently since the 2018 papers on Bell Beakers and Europeans, Corded Ware, or Fennoscandia among others) the most straightforward interpretation of all results published in population genomics research.
NOTE. The finding of a specific type of ancestry in one isolated 40,000-year-old sample from Tianyuan can offer very interesting information on potential population movements to the region. However, the identification of ethnolinguistic communities and their migrations among neighbouring groups in Neolithic or Bronze Age groups is evidently not that simple.
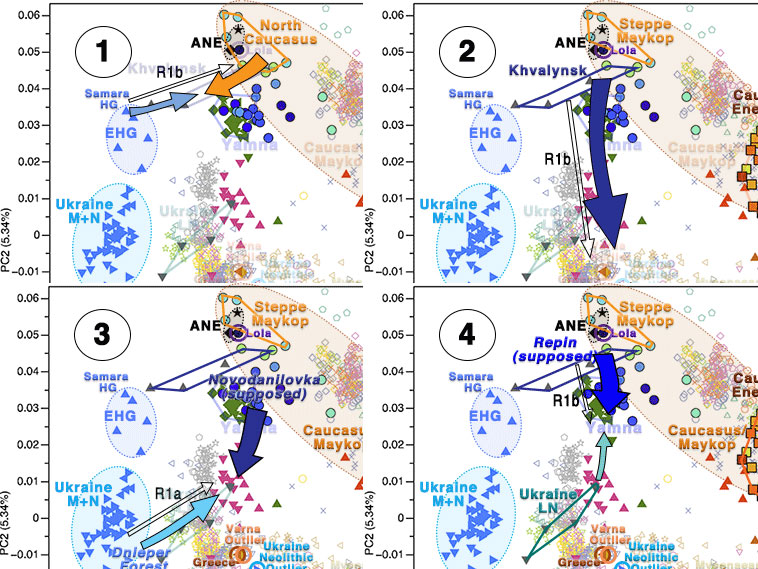
It is becoming more and more clear with each paper that the true “Yamnaya ancestry” – not the originally described one – was in fact associated with Indo-Europeans (see more on the very Yamnaya-like Yamna Hungary and early East Bell Beaker R1b samples, all of quite similar ancestry and PCA cluster before their further admixture with EEF- and CWC-like groups).
The so-called “steppe ancestry”, on the other hand, reflects the contribution of a Northern Caucasus-related ancestry to expanding Khvalynsk settlers, who spread through the steppes more than a thousand years before the expansion of Late Proto-Indo-Europeans with late Repin, and can thus be found among different groups related to the Pontic-Caspian steppes (see more on the emergence and evolution of “steppe ancestry”).
In fact, after the Yamna/Indo-European and Corded Ware/Uralic expansions, it is more likely to find “steppe ancestry” to the north and east in territories traditionally associated with Uralic languages, whereas to the south and west – i.e. in territories traditionally associated with Indo-European languages – it is more likely to find “EEF ancestry” with diminished “steppe ancestry”, among peoples patrilineally descended from Yamna settlers.
Y-DNA haplogroups, the only uniparental markers (see exceptions in mtDNA inheritance) – unlike ancestry percentages based on the comparison of a few samples and flawed study designs – do not admix, do not change, and therefore they do not lend themselves to infinite pet theories (see e.g. what David Reich has to say about R1b-P312 in Iberia directly derived from Yamna migrants in spite of their predominant EEF ancestry): their cultural continuity can only be challenged with carefully threaded linguistic, archaeological, and genetic data.
Related
- A very “Yamnaya-like” East Bell Beaker from France, probably R1b-L151
- “Steppe ancestry” step by step: Khvalynsk, Sredni Stog, Repin, Yamna, Corded Ware
- East Bell Beakers, an in situ admixture of Yamna settlers and GAC-like groups in Hungary
- The Caucasus a genetic and cultural barrier; Yamna dominated by R1b-M269; Yamna settlers in Hungary cluster with Yamna
- Immigration and transhumance in the Early Bronze Age Carpathian Basin
- Steppe and Caucasus Eneolithic: the new keystones of the EHG-CHG-ANE ancestry in steppe groups
- Dzudzuana, Sidelkino, and the Caucasus contribution to the Pontic-Caspian steppe
- On the origin of haplogroup R1b-L51 in late Repin / early Yamna settlers
- On the origin and spread of haplogroup R1a-Z645 from eastern Europe
- Corded Ware culture origins: The Final Frontier
- Sredni Stog, Proto-Corded Ware, and their “steppe admixture”
- Kurgan origins and expansion with Khvalynsk-Novodanilovka chieftains
- About Scepters, Horses, and War: on Khvalynsk migrants in the Caucasus and the Danube
- The concept of “Outlier” in Human Ancestry (III): Late Neolithic samples from the Baltic region and origins of the Corded Ware culture