Razib Khan reports on his new website about an article by Tony Joseph, Who built the Indus Valley civilisation?, itself referring to the potential upcoming results of a genetic analysis project involving Rakhigarhi, the biggest Harappan site.
The possible scenarios based on potential sample results in terms of Y-DNA and mtDNA haplogroups seem to be generally well described, and I would bet – like Khan – for some kind of an East-West Eurasian connection. This is all pure speculation, though, and after all we only have to wait one month and see.
{kind=link}
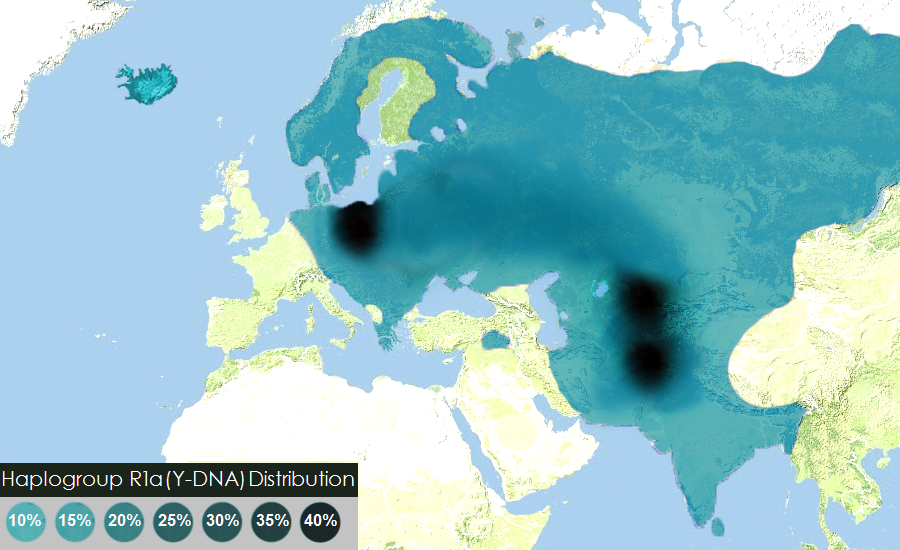
Out of the potential models laid out by Joseph something struck me as plainly wrong. From the section about R1a and Vedic Aryans (emphasis mine):
In the ancient DNA from Rakhigarhi, scientists identify R1a, one of the hundreds of Y-DNA haplogroups (or male lineages that are passed on from fathers to sons). They also identify H2b — one of the hundreds of mt-DNA haplogroups (or female lineages that are passed on from mothers to daughters) — that has often been found in proximity to R1a.
There is no reason whatsoever to think that this would be the research finding, but if it is, it would cause a global convulsion in the fields of population genetics, history and linguistics. It would also cause great cheer among the advocates of the theory that says that the Indus Valley civilisation was Vedic Aryan.
(…)
And it goes on to postulate reasons why such a big fuss will be created about the potential finding of haplogroup R1a, and its implications for the Out-of-India Theory. A global convulsion, no less.
But, since when do genetic findings cause revolutions in Linguistics? Or even in Archaeology?
When I thought the identification of R1a – Indo-European could never reach a lower level of unscientific nonsense, based on circular reasoning, here it is, a worse example.
Not only are there people waiting desperately to see just one sample of an R1a subclade in Yamna to oversimplistically identify (yet again) Corded Ware with the Indo-European expansion; there are also people waiting to find just one sample in India or Central Asia to destroy the current models of steppe origins for Proto-Indo-European.
I guess this childish game is more or less based on the same premises that made some people believe that the concept of the ‘Yamnaya component’ destroyed traditional archaeological models.
It seems that all new methods involving admixture analysis, PCA, and other statistical tools to study Human Ancestry are still irrelevant for most, and indeed that Archaeology and even Linguistics are at the service of the simplistic identification of ancient languages with modern haplogroup distributions.
We are reliving the 1990s in Genetics, and the 1930s in Archaeology and Linguistics all over again. This must be great news for companies that offer genetic analyses… I wonder if it is also good for Science, though.
The funny thing is, the same people responsible for the survival of these misconceptions, i.e. R1a – Indo-European fanboys, who constantly fan the flames of absurd genetic-genealogical and ethnolinguistic identification, are often the first to criticize models compatible with the Out-of-India Theory.
I really hope some R1a subclade is found among the samples, so that stupidity can reach the lowest possible level in discussions among amateur geneticists obsessed with haplogroup R1a’s role in the expansion of Indo-European speakers. Maybe then will the rest of us be able to overcome this renewed moronic supremacist trends hidden behind supposedly objective migration models.
For those interested in actual Indo-European migration models, the finding of early R1a subclades in central Asia (or India) – like the potential finding of R1a subclades in Yamna – does change neither Archaeology nor Linguistics on the Indo-European question.
Genomics is merely helping these disciplines evolve, by supporting certain archaeological models of migration over others, but no revolution has been seen yet, and none is expected.
Each new genetic paper helps support the strongest archaeological models of steppe origins for Proto-Indo-European, and a Late Indo-European expansion compatible with current Linguistic reconstructions.
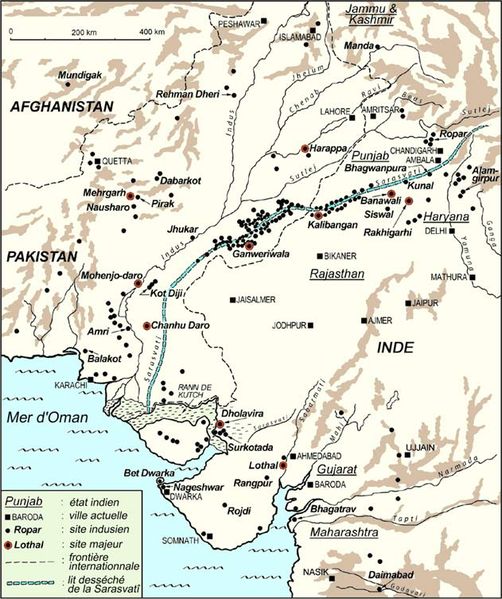
Featured image: From Wikipedia, Indus Valley Civilization, Mature Phase (2600-1900 BCE), by Jane McIntosh.
.png){kind=link}
Related:
- Indo-European demic diffusion model, 3rd edition (revised October 2017)
- The Aryan migration debate, the Out of India models, and the modern “indigenous Indo-Aryan” sectarianism
- New Ukraine Eneolithic sample from late Sredni Stog, near homeland of the Corded Ware culture
- Indo-European and Central Asian admixture in Indian population, dependent on ethnolinguistic and geodemographic divisions
- Asian ancestry of the Roma people in Europe
- The renewed ‘Kurgan model’ of Kristian Kristiansen and the Danish school: “The Indo-European Corded Ware Theory”
- Germanic–Balto-Slavic and Satem (‘Indo-Slavonic’) dialect revisionism by amateur geneticists, or why R1a lineages *must* have spoken Proto-Indo-European