Recent paper (behind paywall) Marmot incisors and bear tooth pendants in Volosovo hunter-gatherer burials. New radiocarbon and stable isotope data from the Sakhtysh complex, Upper-Volga region, by Macānea, Nordqvist, and Kostyleva, J. Archaeol. Sci. (2019) 26:101908.
Interesting excerpts (emphasis mine):
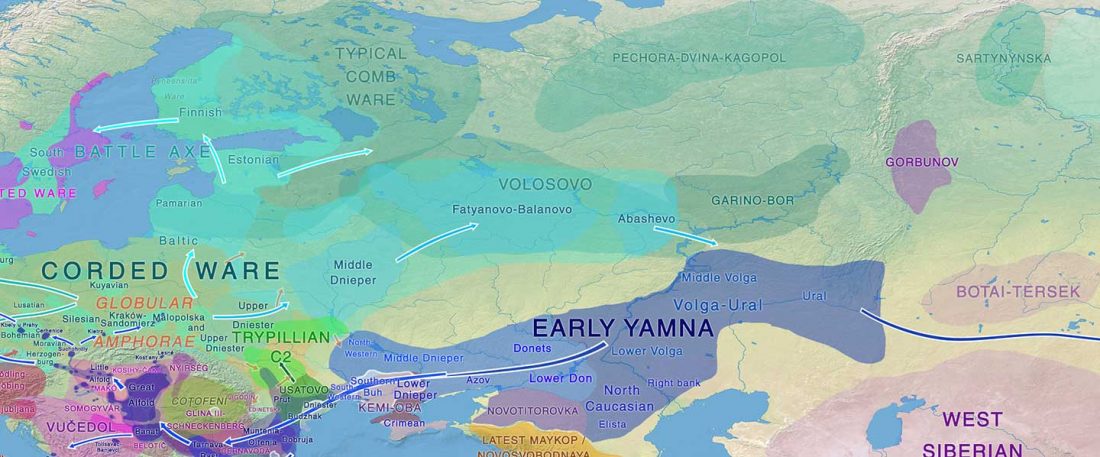
… Read the rest “Volosovo hunter-gatherers started to disappear earlier than previously believed”The Sakhtysh micro-region is located in the Volga-Oka interfluve, along the headwaters of the Koyka River in the Ivanovo Region, central European Russia (Fig. 1). The area has evidence of human habitation from the Early Mesolithic to the Iron Age, and includes altogether 11 long-term and seasonal settlements (Sakhtysh I–II, IIa, III–IV, VII–XI, XIV) and four artefact scatters (sites