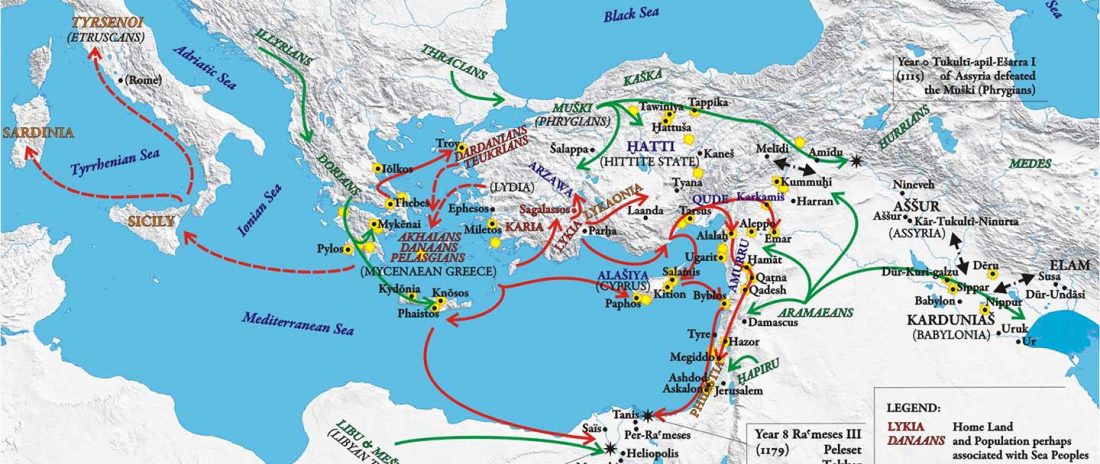
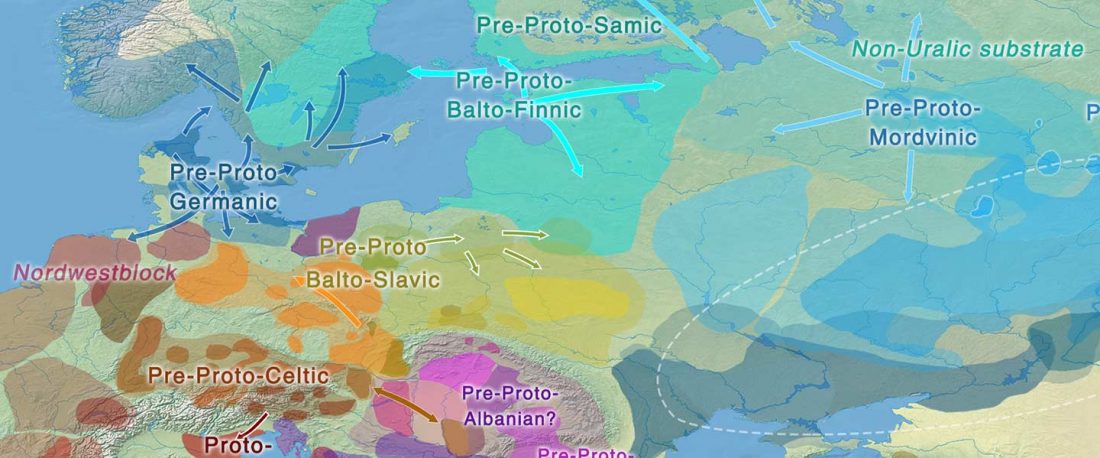
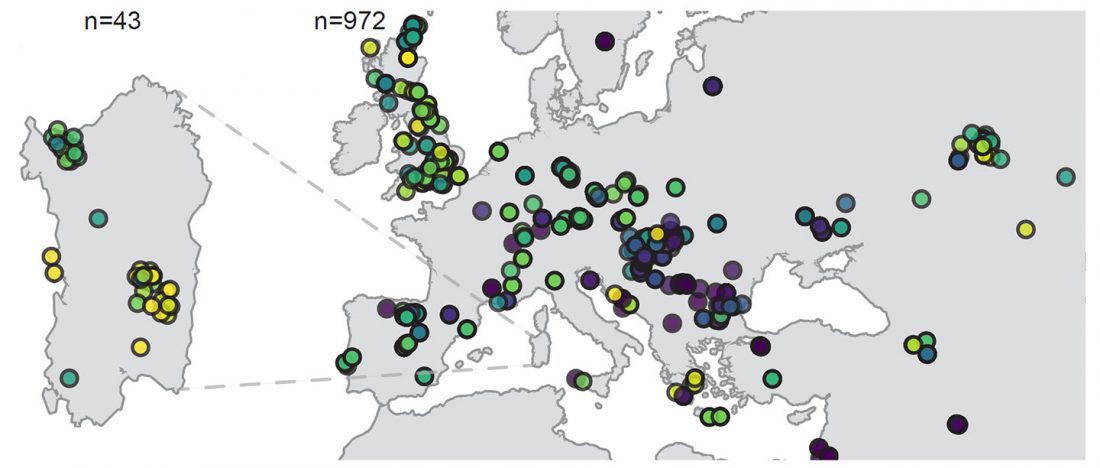
This is a Proto-Indo-European translation of the first lines of the first book I did some time ago. Fernando López-Menchero was kind enough to help with comments and corrections.
For relevant comments and alternative translations for each line, as well as other modern translations, see the Google Sheet.
NOTE. If you are interested in collaborating by editing the document, please contact me.
The structure of the interlinear texts below is as follows:
1. The Ancient Greek version is copied verbatim from Perseus Digital Library, including links to each word to facilitate immediate reference when necessary.
2. The … Read the rest “Interlinear Homer, Iliad 1:1-21 in Mycenaean & Indo-European”