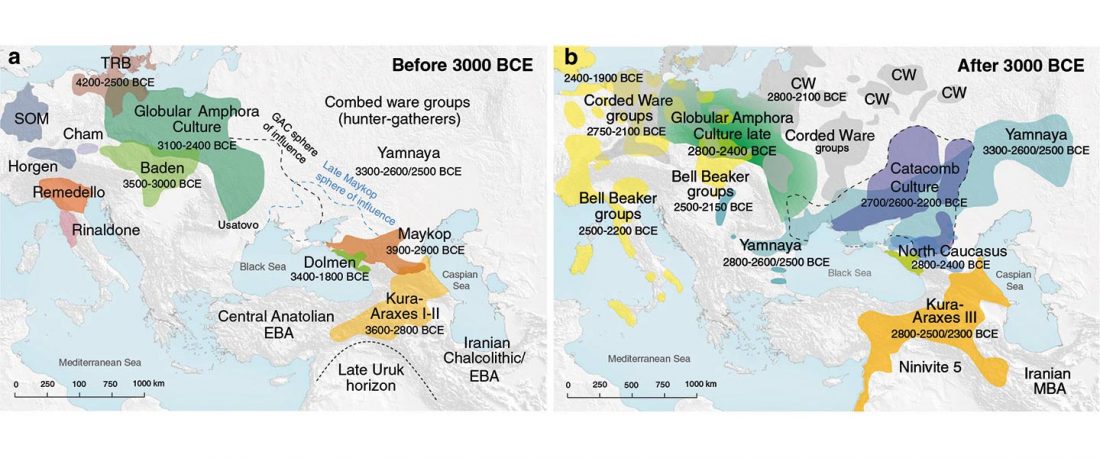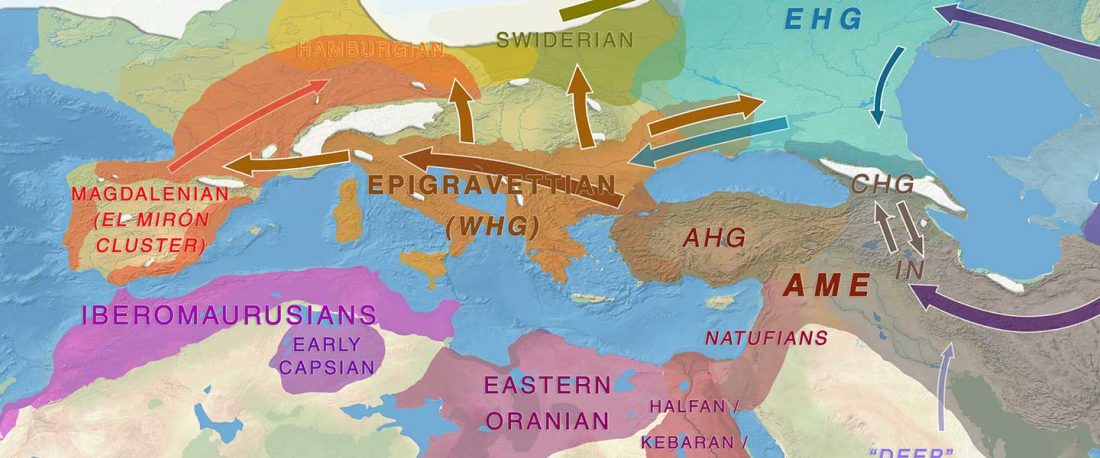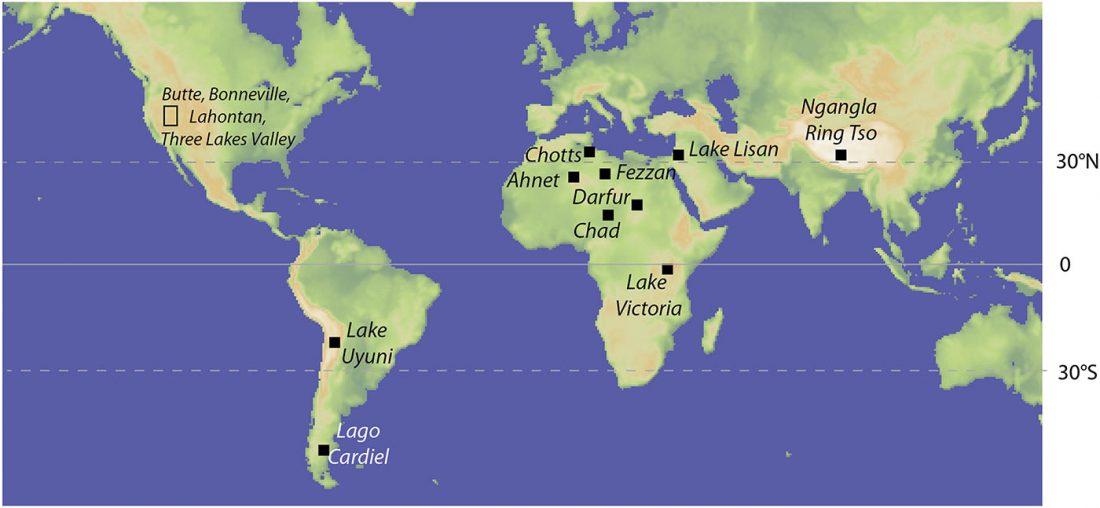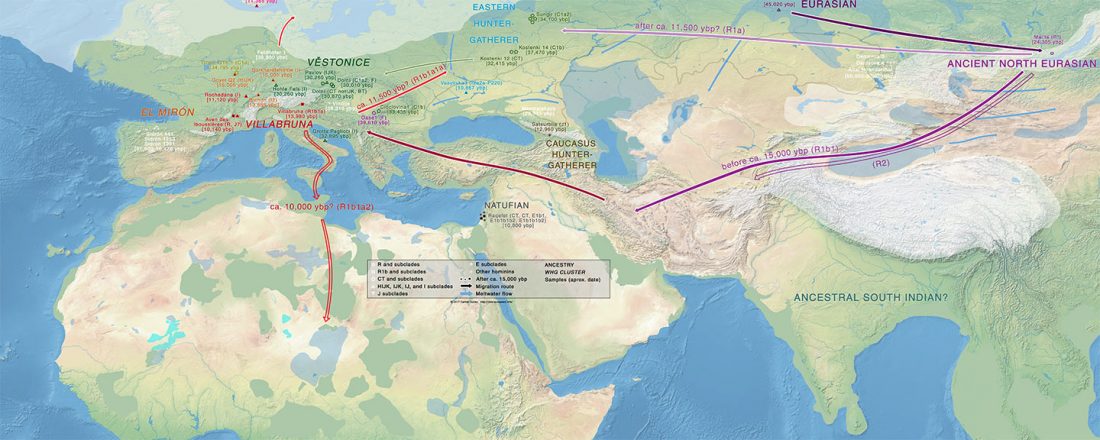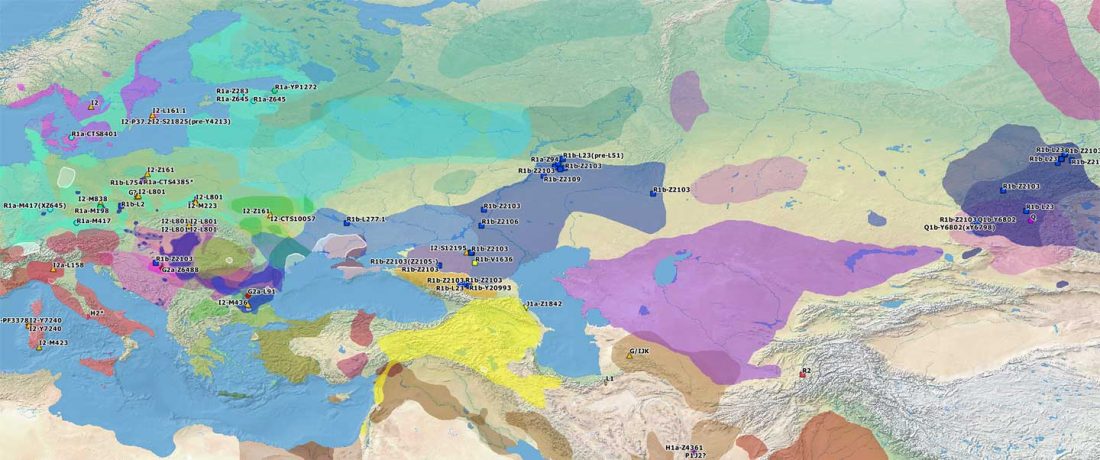
I have compiled for two years now the reported Y-DNA and mtDNA haplogroups of ancient DNA samples published, including also SNPs from analysis of the BAM files by hobbyists.
Y-DNA timeline
Here is a video with a timeline of the evolution of Indo-European speakers, according to what is known today about reconstructed languages, prehistoric cultures and ancient DNA:
NOTE. The video is best viewed in HD 1080p (1920×1080) with a display that allows for this or greater video quality, and a screen big enough to see haplogroup symbols, i.e. tablet or greater. The YouTube link is here. The … Read the rest “The expansion of Indo-Europeans in Y-chromosome haplogroups”