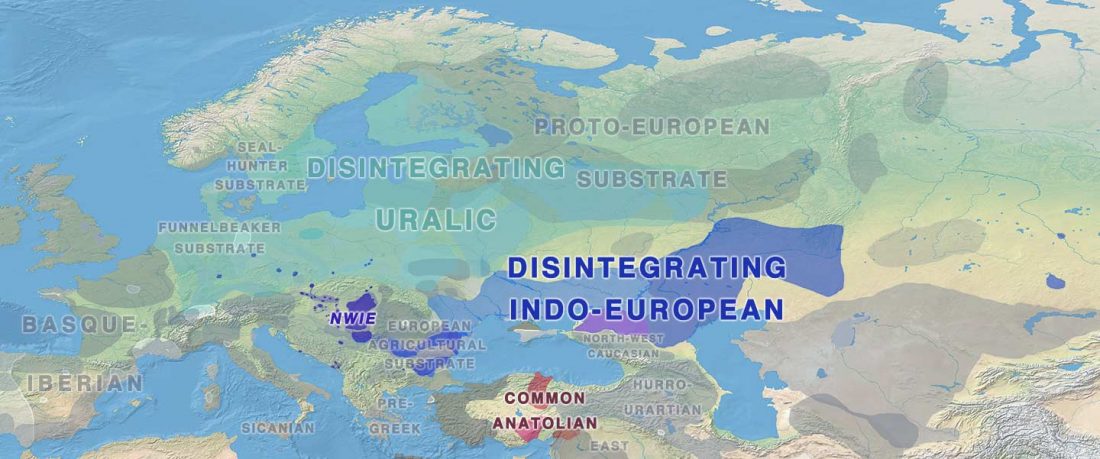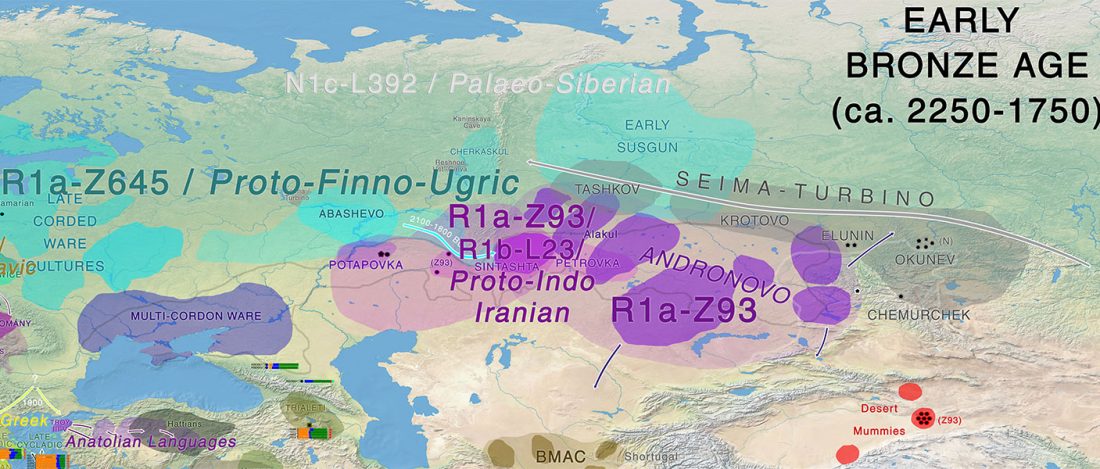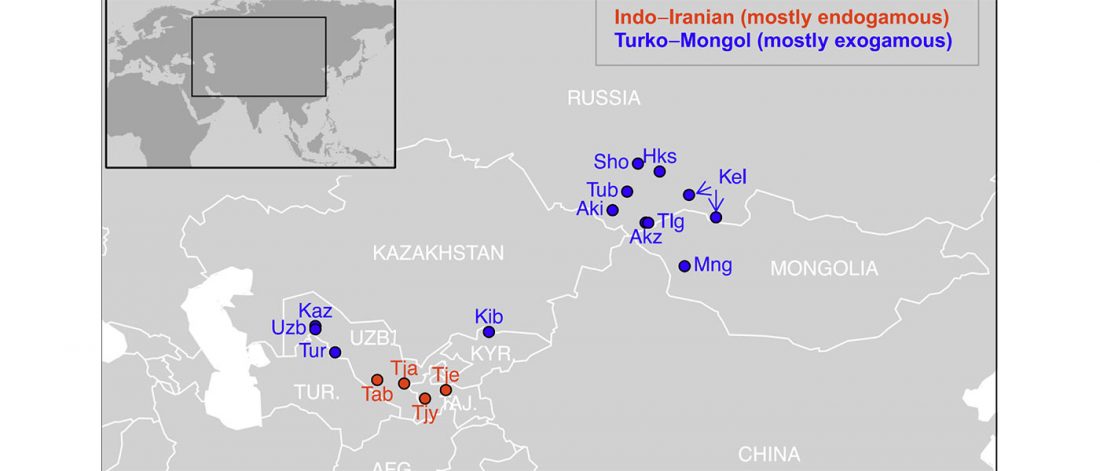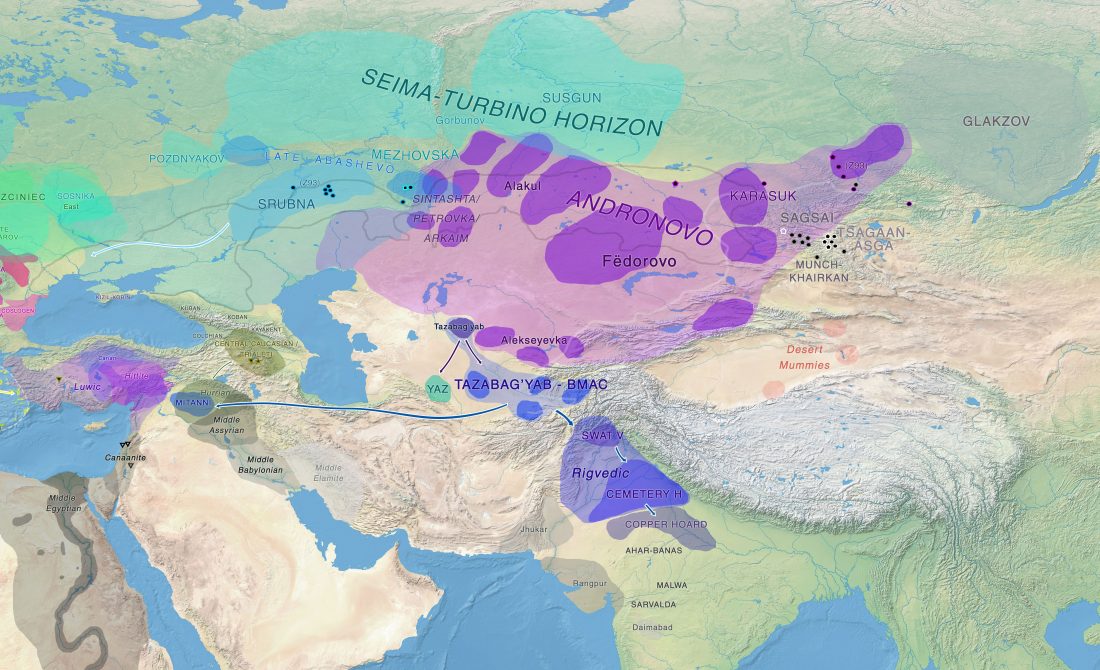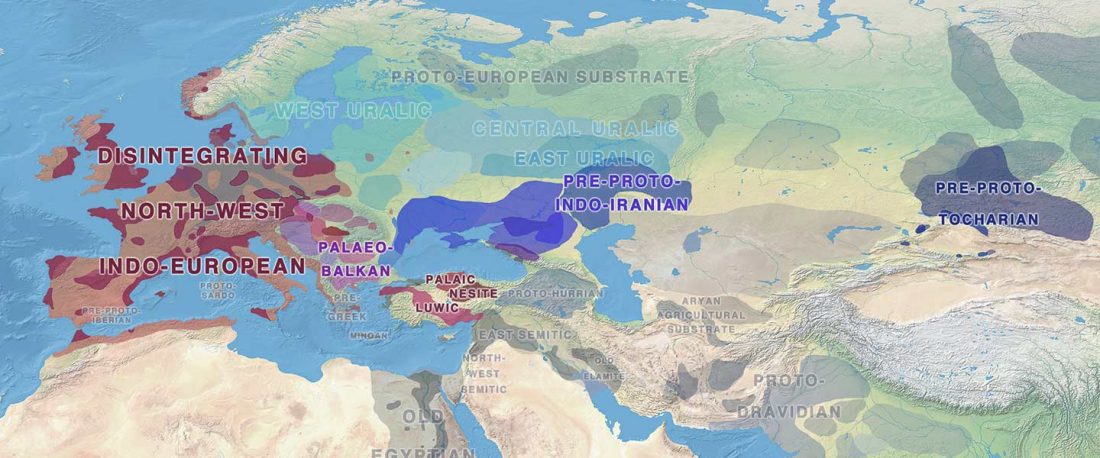
One of the most interesting aspects for future linguistic research, boosted by the current knowledge in population genomics, is the influence of Uralic – most likely spread initially with Corded Ware peoples across northern Europe – on early Indo-European dialects.
Whereas studies on the potential Afroasiatic (or Semitic), Vasconic, Etruscan, or non-Indo-European in general abound for ancient and southern IE branches (see e.g. more on the NWIE substrate words), almost exclusively Uralicists have dealt with the long-term mutual influences between Indo-European and Uralic dialects, and often mostly from the Uralic side.… Read the rest “Early Uralic – Indo-European contacts within Europe”