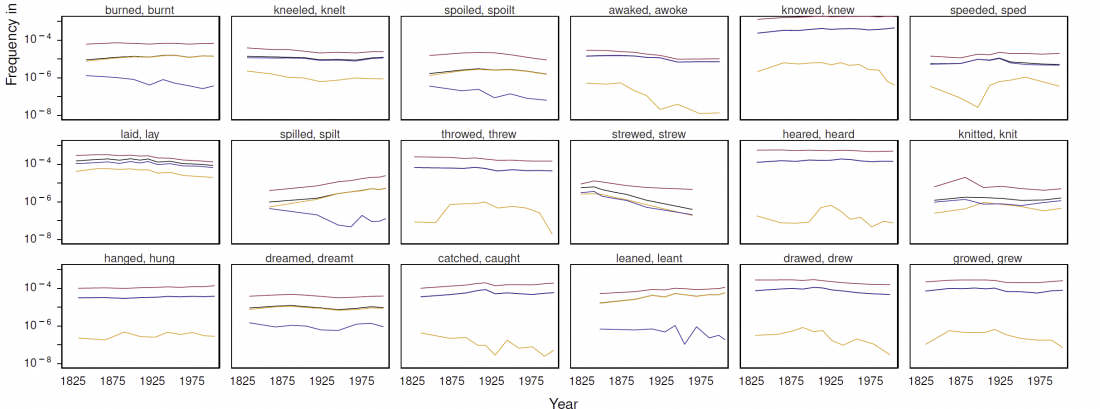
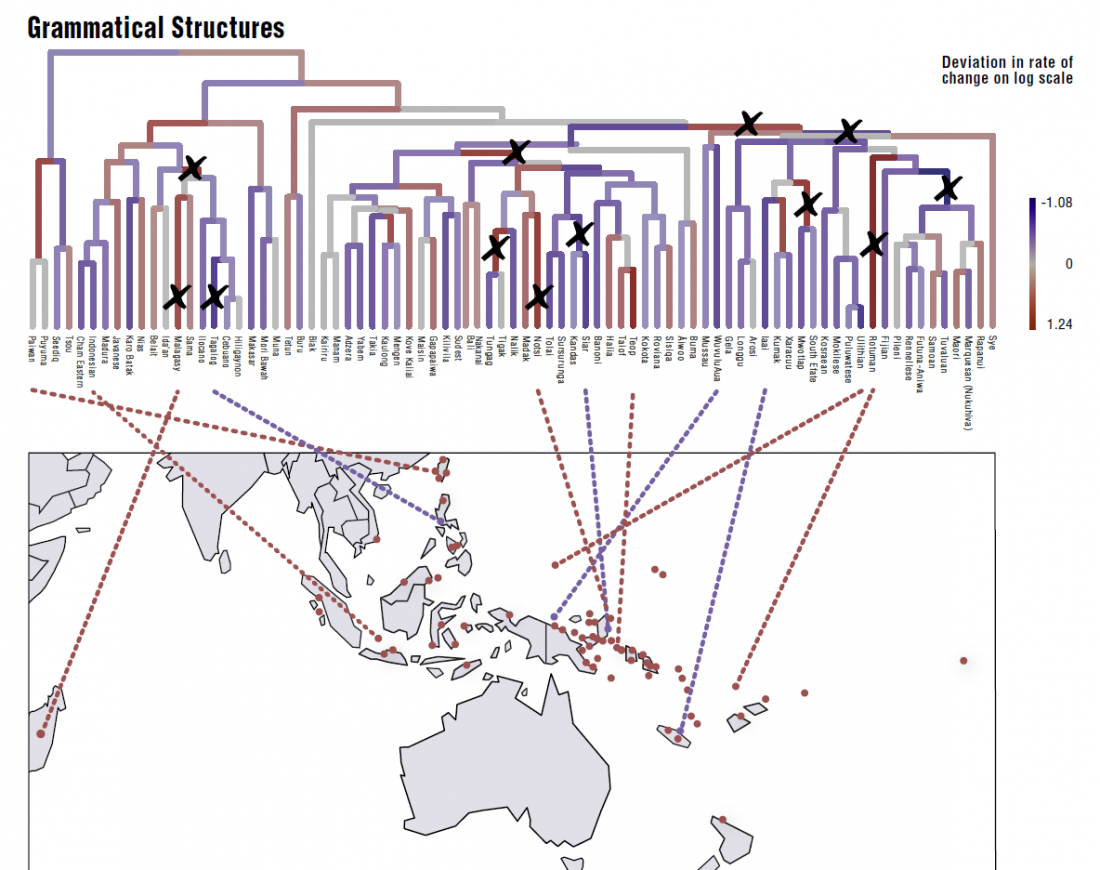
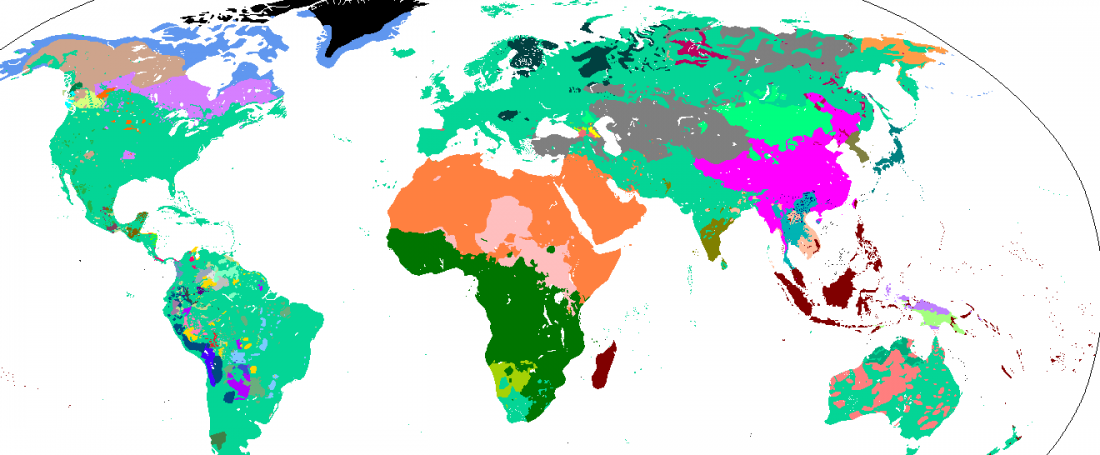
Fernando López-Menchero has just published the first part of his A Practical Guidebook for Modern Indo-European Explorers (2018).
It is a great resource to learn Late Proto-Indo-European as a modern language, from the most basic level up to an intermediate level (estimated B1–B2, depending on one’s previous background in Indo-European and classical languages).
Instead of working on unending details and discussions of the language reconstruction, it takes Late Proto-Indo-European as a learned, modern language that can be used for communication, so that people not used to study with university manuals on comparative grammar can learn almost everything necessary about PIE … Read the rest “A Late Proto-Indo-European self-learning language course”