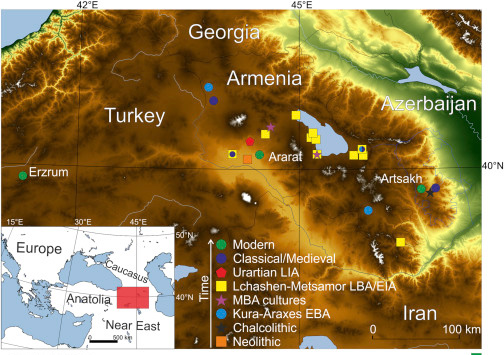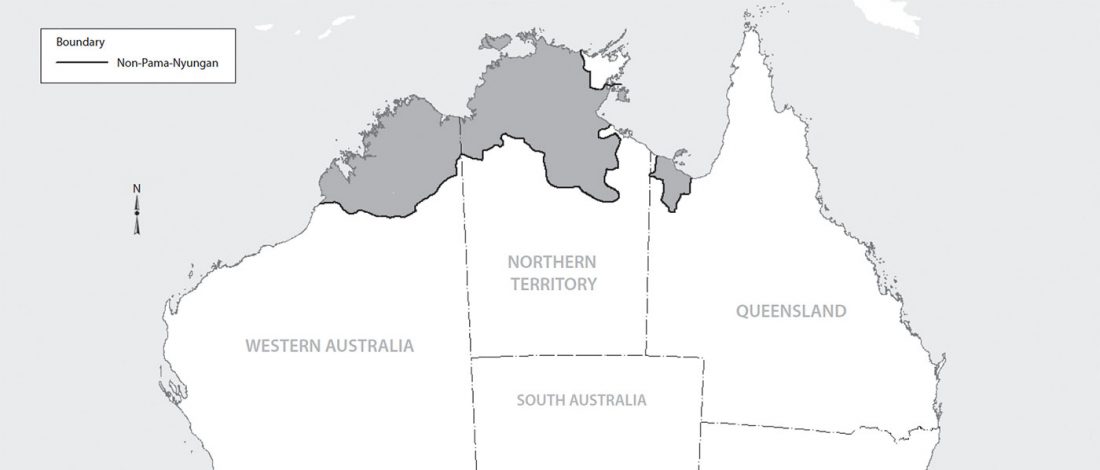
Reconstructing remote relationships – Proto-Australian noun class prefixation, by Mark Harvey & Robert Mailhammer, Diachronica (2017) 34(4): 470–515
Abstract:
… Read the rest “Statistical methods fashionable again in Linguistics: Reconstructing Proto-Australian dialects”Evaluation of hypotheses on genetic relationships depends on two factors: database size and criteria on correspondence quality. For hypotheses on remote relationships, databases are often small. Therefore, detailed consideration of criteria on correspondence quality is important. Hypotheses on remote relationships commonly involve greater geographical and temporal ranges. Consequently, we propose that there are two factors which are likely to play a greater role in comparing hypotheses of chance, contact and inheritance for remote relationships: (i) spatial distribution of corresponding forms;