A new interesting paper from Nature: Detecting evolutionary forces in language change, by Newberry, Ahern, Clark, and Plotkin (2017). Discovered via Science Daily.
The following are excerpts of materials related to the publication (written by Katherine Unger Baillie), from The University of Pennsylvania:
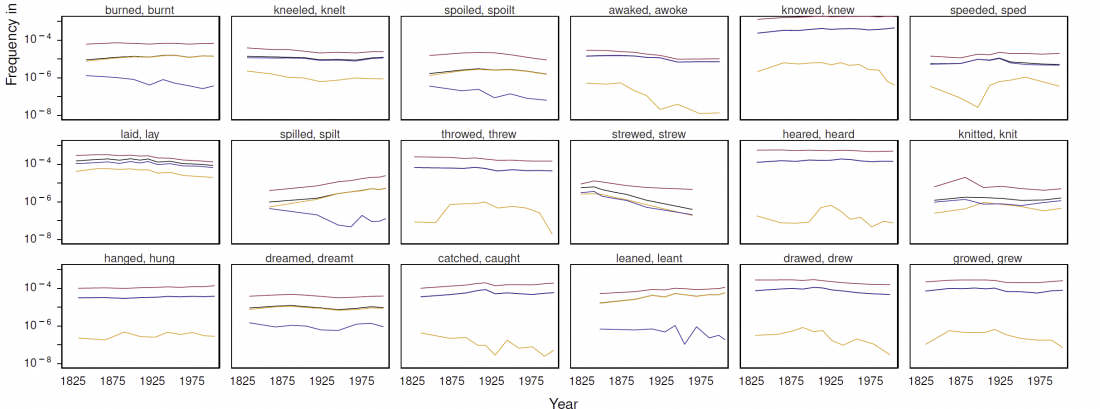
… Read the rest “Evolutionary forces in language change depend on selective pressure, but also on random chance”Examining substantial collections of annotated texts dating from the 12th to the 21st centuries, the researchers found that certain linguistic changes were guided by pressures analogous to natural selection — social, cognitive and other factors — while others seem to have occurred purely by happenstance.
“Linguists usually assume that when a change occurs in